50 Years of SPIE Medical Imaging! A Paper by Siewerdsen and Linte Recount the Impact in Image-Guided Procedures
 SPIE Medical Imaging is celebrating its 50th year anniversary as one of the most important scientific forums for Medical imaging research. Among the conferences at the SPIE Medical Imaging Symposium is the conference now titled Image-Guided Procedures, Robotic Interventions, and Modeling – though its name has evolved through at least nine iterations over the last 30 years. The important role that the “Image-Guided Procedures” conference has presented is traced in a new paper by Jeff Siewerdsen and Cristian Linte in the Journal of Medical Imaging (LINK).
SPIE Medical Imaging is celebrating its 50th year anniversary as one of the most important scientific forums for Medical imaging research. Among the conferences at the SPIE Medical Imaging Symposium is the conference now titled Image-Guided Procedures, Robotic Interventions, and Modeling – though its name has evolved through at least nine iterations over the last 30 years. The important role that the “Image-Guided Procedures” conference has presented is traced in a new paper by Jeff Siewerdsen and Cristian Linte in the Journal of Medical Imaging (LINK).
The origins of the conference are traced from its roots in Image Capture and Display in the late 1980s, and the major themes for which the conference and its proceedings have provided a valuable forum are highlighted. Major themes include image display/visualization, surgical tracking/navigation, surgical robotics, interventional imaging, image registration, and modeling.
Exceptional work from the conference is also highlighted in review of:
- Keynote lectures
- Top 50 most downloaded papers
- Most downloaded paper each year
- Papers earning awards for Best Student Paper and Young Scientist Awards.
Siewerdsen and Linte recount the importance of the conference over the last 30 years, and they look ahead to how the conference will be a vibrant home to burgeoning technologies, algorithms, and markets related to image-guided procedures, robot-assisted interventions, image-based modeling, and global health.
Jeffrey H. Siewerdsen, Cristian A. Linte, “SPIE Medical Imaging 50th anniversary: Historical review of the Image-Guided Procedures, Robotic Interventions, and Modeling conference,” J. Med. Imag. 9(S1) 012206 (18 April 2022) https://doi.org/10.1117/1.JMI.9.S1.012206
New X-Ray Detector for Cone-Beam CT: Paper by Niral Sheth et al. Shows the Advantages
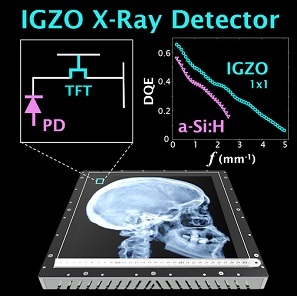 Indirect detection flat-panel detectors (FPDs) consisting of hydrogenated amorphous silicon (a-Si:H) thin-film transistors (TFTs) emerged as the dominant base technology for digital x-ray imaging since the turn of the millennium. However, their performance can be challenged in applications requiring low x-ray exposure, high spatial resolution, and/or high frame rate. Metal oxide TFTs are characterized by smaller size, lower electronic noise, and higher charge mobility compared to conventional a-Si:H TFTs, while retaining advantages of radiation damage resistance and fabrication cost compared to crystalline-based sensors.
Indirect detection flat-panel detectors (FPDs) consisting of hydrogenated amorphous silicon (a-Si:H) thin-film transistors (TFTs) emerged as the dominant base technology for digital x-ray imaging since the turn of the millennium. However, their performance can be challenged in applications requiring low x-ray exposure, high spatial resolution, and/or high frame rate. Metal oxide TFTs are characterized by smaller size, lower electronic noise, and higher charge mobility compared to conventional a-Si:H TFTs, while retaining advantages of radiation damage resistance and fabrication cost compared to crystalline-based sensors.
A recent paper by Niral Sheth et al. (LINK) published in Medical Physics evaluates the performance of a newly introduced FPD based on indium gallium zinc oxide (IGZO) TFTs. The studies quantify how the intrinsic material advantages of IGZO translate to 2D and 3D imaging performance and provide insight for use in various clinical applications.
The technical assessment begins with evaluation of 2D imaging performance pertinent to fluoroscopic imaging – factors such as dark noise, gain, linearity, image lag, modulation transfer function (MTF), noise-power spectrum (NPS), and detective quantum efficiency (DQE). The study extends also to 3D imaging performance in CBCT – factors such as soft-tissue contrast-to-noise ratio (CNR), 3D MTF, 3D NPS, and 3D noise-equivalent quanta (NEQ). Overall, the IGZO FPD demonstrated improvements in electronic noise, image lag, and NEQ characteristics that amounted to ~10-30% improvement in CNR and extension of the low-dose operating range compared to a conventional a-Si:H FPD.
A selection of clinical imaging scenarios was further investigated in anthropomorphic phantoms to interpret the technical findings and identify conditions where the performance advantages of the IGZO FPD were visually evident with respect to a particular clinical task. Notable improvements were observed for the IGZO FPD in scenarios simulating CBCT imaging of intracranial hemorrhage (detection of blood in the brain), thoracic imaging (low-dose CBCT of the chest), and prostate localization (soft-tissue delineation in image-guided radiation therapy or interventional radiology). The results suggest that IGZO FPDs could facilitate new fluoroscopic and CBCT imaging capabilities and clinical applications that require low radiation dose, high spatial resolution, and/or high frame rate.
The paper was published in Medical Physics, April 2022 – DOI: 10.1002/mp.15605 (LINK)
 Dr. Runze Han – PhD Dissertation on 3D Image Registration at Hopkins BME
Dr. Runze Han – PhD Dissertation on 3D Image Registration at Hopkins BME
Runze Han (PhD student in Biomedical Engineering at Johns Hopkins University) successfully defended his PhD thesis entitled, “Advanced Motion Models for Rigid and Deformable Registration in Image-Guided Interventions” in March 2022. Congratulations, Dr. Han!
Runze’s work spanned a range of computational algorithms and motion models for 3D image registration with applications in orthopaedic surgery and neurosurgery. For orthopaedic surgery, he developed statistical shape models (available for download at the I-STAR Labs: LINK) for automatic segmentation of the pelvis and sacrum and automatic preoperative planning of surgical trajectories in pelvic trauma surgery. He extended classic, single-body rigid 3D-3D and 3D-2D registration models to novel forms of multi-body registration for accurate guidance of fracture reduction. Drawing directly from intraoperative 2D imaging – without introduction of conventional tracking systems – the ability to reduce complex, multi-body pelvic fractures could offer improved surgical precision, safety, and patient outcomes in trauma surgery. His work on such registration models was published in:
- Han, R., Uneri, A., De Silva, T., Ketcha, M., Goerres, J., Vogt, S., Kleinszig, G., Osgood, G., Siewerdsen, J. H. “Atlas-based automatic planning and 3D–2D fluoroscopic guidance in pelvic trauma surgery”. Physics in Medicine & Biology, vol 64(9):095022, 2019. (LINK)
- Han, R., Uneri, A., Vijayan, R., Sheth, N., Wu, P., Vagdargi, P., Vogt, S., Kleinszig, G., Osgood, G. M., Siewerdsen, J. H. “Multi-Body 3D-2D Registration for Image-Guided Reduction of Pelvic Dislocation in Orthopaedic Trauma Surgery”. Physics in Medicine & Biology vol 65(13):135009, 2020. (LINK)
- Han, R., Uneri, A., Vijayan, R., Wu, P., Vagdargi,, P., Sheth, N., Vogt, S., Kleinszig, G., Osgood, G. M., Siewerdsen, J. H., “A Multi-Body Image Registration Framework for Pelvic Fracture Reduction Planning and Guidance in Orthopaedic Trauma Surgery.” Medical Image Analysis, vol 68, 2021. (LINK)
Runze continued the theme of developing increasingly sophisticated registration models via new forms of 3D-3D deformable registration based on the Demons algorithm and novel deep learning architectures – each in application to image-guided neurosurgery. He incorporated momentum-based optimization within the Demons algorithm to speed runtime from 15-30 min down to 2.2 min while preserving accuracy (1.5 mm TRE) and diffeomorphism in the deformation of deep brain structures. Going further, Runze developed deep learning registration methods that leveraged an intermediate “synthetic” MR-like and CT-like image domains to achieve accurate deformable registration of MR and CT images. His work culminated with a Joint Synthesis and Registration (JSR) method that registered preoperative MRI to intraoperative CBCT – an especially challenging scenario due to the high levels of artifact, noise, and low contrast that tend to constrain the quality of intraoperative CBCT. Despite such challenges, Runze’s JSR method demonstrated registration accuracy within 2.5 mm and runtime of 2.6 sec. Such work could improve the precision and safety of neurosurgical procedures such as tumor biopsy / resection and deep brain stimulation. His work on deformable registration models was published in:
- Han, R., De Silva, T., Ketcha, M., Uneri, A., Siewerdsen, J. H. “A momentum-based diffeomorphic demons framework for deformable MR-CT image registration”. Physics in Medicine & Biology, vol 63(21): 215006, 2018.
- Han, R., Jones, C. K., Lee, J., Wu, P., Vagdargi, P., Uneri, A., Helm, P. A., Luciano, M., Anderson, W. S., Siewerdsen, J. H. “Deformable MR-CT image registration using an unsupervised, dual-channel network for neurosurgical guidance”. Medical Image Analysis, vol 75:102292, 2022.
- Han, R., Jones, C. K., Lee, J., Zhang, X., Wu, P., Vagdargi, P., Uneri, A., Helm, P. A., Luciano, M., Anderson, W. S., & Siewerdsen, J. H. ” Joint Synthesis and Registration Network for Deformable MR-CBCT Image Registration for Neurosurgical Guidance “. Physics in Medicine & Biology (under revision).
Having successfully defended his dissertation, Dr. Han is moving on to the next step in his career at Intuitive Surgical (Sunnyvale CA), where his work will focus on image-guided surgical robotics.
Congratulations, Dr. Han!
The I-STARs Align at SPIE Medical Imaging 2022
 The annual SPIE Medical Imaging Symposium held in February 2022 features 12 talks from the I-STAR Lab and collaborators in Biomedical Engineering, Radiology, Neurosurgery, and Orthopaedic Surgery at Johns Hopkins University.
The annual SPIE Medical Imaging Symposium held in February 2022 features 12 talks from the I-STAR Lab and collaborators in Biomedical Engineering, Radiology, Neurosurgery, and Orthopaedic Surgery at Johns Hopkins University.
Presentations include:
Control of variance and bias in CT image processing with variational training of deep neural networks
Matthew Tivnan, Wenying Wang, Grace Gang, Peter Noël, J. Webster Stayman | 21 February 2022 • 2:10 PM – 2:30 PM PST
Sampling effects for emerging cone-beam CT systems and scan trajectories: from Tuy’s condition to system design and routine image quality tests
Aina Tersol , Pengwei Wu, Rolf Clackdoyle, John M. Boone, Jeffrey H. Siewerdsen | 21 February 2022 • 6:00 PM – 7:30 PM PST
Deformable registration of MRI to intraoperative cone-beam CT of the brain using a joint synthesis and registration network
Runze Han, Craig K. Jones, Pengwei Wu, Prasad Vagdargi, Xiaoxuan Zhang, Ali Uneri, Junghoon Lee, Mark M. Luciano, William S. Anderson, Patrick Helm, Jeffrey H. Siewerdsen | 22 February 2022 • 11:50 AM – 12:10 PM PST
Targeted deformable motion compensation for vascular interventional cone-beam CT imaging
Alejandro Sisniega, Alexander Lu, Heyuan Huang, Wojciech Zbijewski, Mathias Unberath, Clifford R. Weiss, Jeffrey H. Siewerdsen | 22 February 2022 • 1:40 PM – 2:00 PM PST
Non-circular CBCT orbit design and realization on a clinical robotic C-arm for metal artifact reduction
Yiqun Ma, Grace J. Gang, Tina Ehtiati, Tess Reynolds, Tom Russ, Wenying Wang, Clifford Weiss, Nicholas Theodore, Kelvin Hong, Joseph W. Stayman, Jeffrey H. Siewerdsen | 22 February 2022 • 1:40 PM – 2:00 PM PST
Robot-assisted neuroendoscopy for real-time 3D guidance of transventricular approach to deep-brain targets
Prasad Vagdargi, Ali Uneri, Craig K. Jones, Pengwei Wu, Runze Han, Mark G. Luciano, William S. Anderson, Patrick A. Helm, Gregory D. Hager, Jeffrey H. Siewerdsen | 22 February 2022 • 2:20 PM – 2:40 PM PST
Feasibility of dual-energy cone-beam CT of bone marrow edema using dual-layer flat panel detectors
Stephen Z. Liu, Chumin Zhao, Magdalena Herbst, Thomas Weber, Sebastian Vogt, Ludwig Ritschl, Steffen Kappler, Wojciech Zbijewski, Jeffrey H. Siewerdsen | 22 February 2022 • 2:20 PM – 2:40 PM PST
Performance assessment framework for neural network denoising
Junyuan Li, Wenying Wang, Matthew Tivnan, Grace J. Gang, Joseph W. Stayman | 23 February 2022 • 11:10 AM – 11:30 AM PST
Data-dependent nonlinearity analysis in CT denoising CNNs
Wenying Wang, Matthew Tivnan, Junyuan Li, Joseph W. Stayman, Grace J. Gang | 23 February 2022 • 11:50 AM – 12:10 PM PST
Automatic labeling of vertebrae in long-length intraoperative imaging with a multi-view, region-based CNN
Yixuan Huang, Craig K. Jones, Xiaoxuan Zhang, Ashley Johnston, Nafi Aygun, Timothy Witham, Patrick A. Helm, Patrick A. Helm, Ali Uneri, Jeffrey H. Siewerdsen | 23 February 2022 • 1:40 PM – 2:00 PM PST
Motion-compensated targeting in pulmonary interventions using cone-beam CT and locally rigid / globally deformable 3D-2D registration
Rohan C. Vijayan, Niral Sheth, Lina Mekki, Alexander Lu, Ali Uneri, Alejandro Sisniega, Jessica Maggaragia, Sebastian Vogt, Jeffrey Thiboutot, Hans Lee, Lonny Yarmus, Jeffrey Siewerdsen | 23 February 2022 • 5:30 PM – 7:00 PM PST
Statistical shape and pose modeling for automated planning in robot-assisted reduction of the ankle syndesmosis
Ali Uneri, Corey Simmerer, Runze Han, Gerhard Kleinszig, Gerhard Kleinszig, Kevin Cleary, Babar Shafiq, Wojciech Zbijewski, Jeffrey H. Siewerdsen | 24 February 2022 • 1:40 PM – 2:00 PM PST
As Co-Chair of the Image-Guided Procedures conference, Professor Siewerdsen participated on panel discussions for both the Medical Imaging 50th Anniversary as well as Careers at the Interface of Physics, Engineering, and Medical Imaging.
Congratulations, Dr. Wu! – PhD Thesis on High-Quality Cone-Beam CT
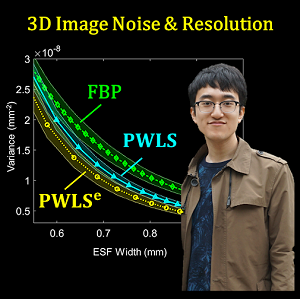 Pengwei Wu (PhD Student in Hopkins BME) successfully defended his doctoral dissertation at Hopkins BME – Congratulations, Dr. Wu!
Pengwei Wu (PhD Student in Hopkins BME) successfully defended his doctoral dissertation at Hopkins BME – Congratulations, Dr. Wu!
Pengwei tackled questions about his dissertation entitled “Improved Image Quality In Cone-Beam Computed Tomography for Image-Guided Interventions.”
Pengwei’s work tackles major challenges in the image quality of cone-beam computed tomography (CBCT) – specifically aiming to advance contrast resolution beyond conventional limitations to a level that reliably permits low-contrast soft-tissue visualization.
As detailed in publications listed below, Pengwei’s dissertation involved development and clinical testing of new CBCT imaging systems and 3D image reconstruction algorithms for clinical applications in image-guided neurosurgery and point-of-care imaging in the neurological critical care unit (NCCU). The thesis demonstrates that advanced imaging approaches that incorporate accurate system models, novel artifact reduction methods, and emerging 3D image reconstruction algorithms can effectively tackle current challenges in soft-tissue contrast resolution and expand the application of CBCT in image-guided interventions.
Among the results of his dissertation are:
- Integration of deep learning-based (image synthesis) and physics-based (FBP or MBIR) 3D image reconstruction methods to leverage the strengths of each (called “DL-Recon”);
- A method to automatically define C-arm source-detector orbits to minimize the influence of metal artifacts in 3D image reconstruction (called “MAA” – metal artifact avoidance);
- A penalized-weighted least squares (PWLS) model that includes the effects of electronic noise and dynamic gain for flat-panel detectors;
- A clinical study of CBCT image quality in high-quality imaging of the brain in the NCCU.
Among the publications associated with Pengwei’s dissertation are:
- [Fully 3D Meeting 2021 and arXiv] Using uncertainty in deep learning reconstruction for cone-beam CT of the brain
- [Phys Med Biol 65(16)] C-arm orbits for metal artifact avoidance (MAA) in cone-beam CT
- [Med Phys 47(6)] Cone-beam CT for imaging of the head/brain: Development and assessment of scanner prototype and reconstruction algorithms
- [Med Phys 48(6)] Theory, method, and test tools for determination of 3D MTF characteristics in cone-beam CT
- [Phys Med Biol 63(24)] Statistical weights for model-based reconstruction in cone-beam CT with electronic noise and dual-gain detector readout
Congratulations, Dr. Wu!
Deformable Registration of Brain MRI and CT with Deep Learning
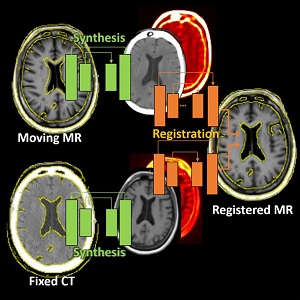 Runze Han (PhD student at Hopkins BME) and coauthors have reported a new deep-learning method that tackles deformable registration between MRI and CT images of the brain for neuro-navigation. This uses unsupervised image synthesis and registration neural networks and exceeds the performance of previously reported methods while reducing runtime to 3 seconds. More information and results are detailed in their paper published in Medical Image Analysis (LINK).
Runze Han (PhD student at Hopkins BME) and coauthors have reported a new deep-learning method that tackles deformable registration between MRI and CT images of the brain for neuro-navigation. This uses unsupervised image synthesis and registration neural networks and exceeds the performance of previously reported methods while reducing runtime to 3 seconds. More information and results are detailed in their paper published in Medical Image Analysis (LINK).
The method involves an image synthesis subnetwork using probabilistic Cycle-GAN for MR-CT cross-domain mapping and a dual-channel registration subnetwork fusing the contributions from the MR and CT channels. While the network incorporates uncertainty estimations from the image synthesis for intelligent spatial fusion, the design of dual-channel fusion and estimations demonstrated particularly higher registration accuracy at small subcortical anatomy than previously reported methods.
The network was tested in digital simulation and retrospective clinical studies of minimally-invasive neurosurgery and was compared to state-of-the-art iterative optimization-based and CNN-based registration algorithms. Superior performance was observed for the proposed method in terms of Dice coefficient, surface distance error, and target registration error. The proposed method was also able to achieve diffeomorphism and fast runtime that would potentially be compatible with the demands of high-precision neurosurgery.
(LINK) Runze Han, Craig K. Jones, Junghoon Lee, Pengwei Wu, Prasad Vagdargi, Ali Uneri, Patrick A. Helm, Mark Luciano, William S. Anderson, Jeffrey H. Siewerdsen, “Deformable MR-CT Image Registration Using an Unsupervised, Dual-Channel Network for Neurosurgical Guidance,” Medical Image Analysis (2021). https://doi.org/10.1016/j.media.2021.102292.
Cone-Beam and Slot-Beam CT: Improved 3D Image Quality and Dose with a Slot Collimator on the O-arm
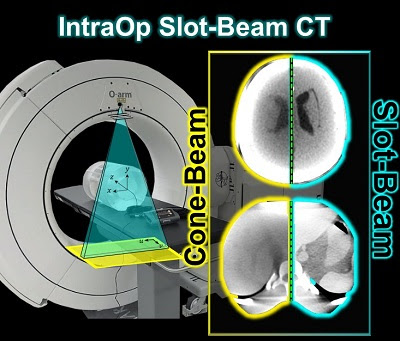 A new paper by Esme Zhang investigates the 3D imaging performance and radiation dose for a prototype slot-beam configuration on an O-arm intraoperative imaging system (Medtronic Inc., Littleton MA). Her work shows the potential for such a system to improve soft-tissue image quality and reduce dose in image-guided surgery.
A new paper by Esme Zhang investigates the 3D imaging performance and radiation dose for a prototype slot-beam configuration on an O-arm intraoperative imaging system (Medtronic Inc., Littleton MA). Her work shows the potential for such a system to improve soft-tissue image quality and reduce dose in image-guided surgery.
A slot collimator was integrated with the O-arm system for slot-beam axial CT. The collimator can be automatically actuated to provide 1.2° slot-beam longitudinal collimation. Cone-beam and slot-beam configurations were investigated with and without an antiscatter grid. Dose, scatter, image noise, and soft-tissue contrast resolution were evaluated in quantitative phantoms for head and body configurations over a range of exposure levels (beam energy and mAs), with reconstruction performed via filtered-backprojection. Imaging performance for various anatomical sites and imaging tasks was assessed with anthropomorphic head, abdomen, and pelvis phantoms.
Slot-beam scans reduced dose by ∼1/5 to 1/3 compared to cone-beam scans, owing primarily to reduced x-ray scatter. The slot-beam provided a ∼6-7× reduction in scatter-to-primary ratio (SPR) compared to cone-beam. Compared to cone-beam scans at equivalent dose, slot-beam images exhibited a ∼2.5× increase in soft-tissue CNR for both grid and gridless configurations.
Slot-beam imaging could benefit certain interventional scenarios in which improved visualization of soft tissues is required within a narrow longitudinal region of interest – e.g., checking the completeness of tumor resection, preservation of adjacent anatomy, or detection of hemorrhage or other complications. While preserving existing capabilities for fluoroscopy and cone-beam CT, slot-beam scanning could enhance the utility of intraoperative imaging and provide a useful mode for safety and validation checks in image-guided surgery.
(Link to paper)Xiaoxuan Zhang, Wojciech Zbijewski , Yixuan Huang, Ali Uneri, Craig K Jones, Sheng-Fu L Lo, Timothy F Witham, Mark Luciano, William Stanley Anderson, Patrick A Helm, Jeffrey H Siewerdsen Med Phys. 2021 Sep 14. doi: 10.1002/mp.15221. Epub ahead of print. PMID: 34519364.
Functional Shapes (FShapes) for Morphometric Analysis of Osteoarthritis: Collaboration with Center for Imaging Science Yields New Insight
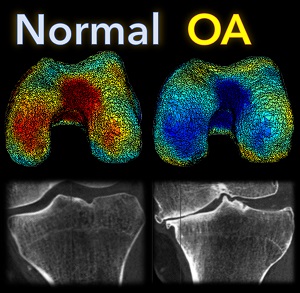 A new paper by Nicolas Charon (Assistant Professor, Center for Imaging Sciences and Applied Mathematics and Statistics at Johns Hopkins University), Asef Islam (undergraduate student in Biomedical Engineering at Johns Hopkins), and Wojtek Zbijewski (Assistant Professor in Biomedical Engineering at Johns Hopkins) investigates the feasibility of using the recently introduced framework of functional shapes (FShapes) to reveal morphological features of knee osteoarthritis (OA).
A new paper by Nicolas Charon (Assistant Professor, Center for Imaging Sciences and Applied Mathematics and Statistics at Johns Hopkins University), Asef Islam (undergraduate student in Biomedical Engineering at Johns Hopkins), and Wojtek Zbijewski (Assistant Professor in Biomedical Engineering at Johns Hopkins) investigates the feasibility of using the recently introduced framework of functional shapes (FShapes) to reveal morphological features of knee osteoarthritis (OA).
The concept of FShapes is promising for applications in OA because it provides a rigorous mathematical framework to simultaneously model the population variability in bone shape – here, the tibial or femoral articular surface – and in a function defined on that shape – here, a map of local joint space width at each point of the surface. Considering that articular degeneration is the hallmark of advanced OA, this approach might, for example, yield new insights into interactions between certain morphological bone variants and development of joint space loss.
The study used a set of three-dimensional knee scans of patients with and without OA. The scans were obtained using a novel weight-bearing extremity Cone Beam CT (CBCT) system at Johns Hopkins. After extracting tibial surface meshes from the CBCT images, each surface was equipped with a joint space map (JSM) using an algorithm based on an electrostatic model of the intra-articular space (previously developed at I-STAR). An atlas estimation procedure in the setting of large diffeomorphic deformation metric mapping (LDDMM) was then applied to obtain a template representing a mean shape and a mean JSM, together with variables that model the shape and JSM transformations from the template to each subject in the dataset. Therein lies another potential advantage of this approach: it is landmark-free because the diffeomorphic transformation model does not require a priori point correspondences between the subjects.
In a preliminary validation study, a support vector machine classifier was applied to the template-subject transformations to find discriminative features associated with OA. The correct classification scores were 85% – 91%, depending on which components of the FShape (shape+JSM, only shape, only JSM) were used. The discriminant directions revealed by this analysis were consistent with prior studies of OA: including medial joint space loss and deepening of the tibial plateau.
The functional shape methodology is a promising new tool for landmark-free morphological analysis in OA and other orthopedic applications where bone shape and alignment are simultaneously involved, ranging from joint disease to fracture healing.
(Link to paper) Nicolas Charon, Asef Islam, and Wojciech Zbijewski, “Landmark-free morphometric analysis of knee osteoarthritis using joint statistical models of bone shape and articular space variability” J. of Medical Imaging, 8(4), 044001 (2021)
Fully-3D Meeting 2021 Features PhD Student Research on 3D Image Reconstruction – and Award Nominees!
 The Fully-3D Meeting (16th International Meeting on Fully 3D Image Reconstruction in Radiology and Nuclear Medicine) features numerous talks from Hopkins BME on advanced 3D image reconstruction methods. Among the research presented at the conference (July 19-23, 2021) are talks from PhD students in the I-STAR and AIAI labs at Hopkins BME.
The Fully-3D Meeting (16th International Meeting on Fully 3D Image Reconstruction in Radiology and Nuclear Medicine) features numerous talks from Hopkins BME on advanced 3D image reconstruction methods. Among the research presented at the conference (July 19-23, 2021) are talks from PhD students in the I-STAR and AIAI labs at Hopkins BME.
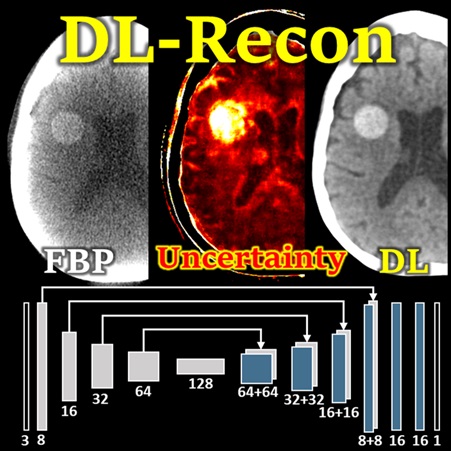
Pengwei Wu (PhD student at Hopkins BME) presents a deep learning reconstruction (DL-Recon) method that integrates physically principled physics-based models (FBP or MBIR) with DL-based image synthesis by incorporating the statistical uncertainty of the synthesized image. Statistical uncertainty in image synthesis is shown to provide a key to leveraging the strengths of DL and physics-based methods, weighting information from the synthesis result in regions where uncertainty is low and information from the physics model in regions where uncertainty is high. In challenging tasks related to cone-beam CT of the brain, the DL-Recon method demonstrated substantial improvements in image noise compared to pure physics model-based methods combined with a strong boost in the contrast and fidelity of lesions that were not well represented in the training data for pure synthesis methods.
(LINK: P. Wu et al., Using Uncertainty in Deep Learning Reconstruction for Cone-Beam CT of the Brain – FULLY3D 2021 AWARD NOMINEE)
Heyuan Huang (PhD student at Hopkins BME) tackles the challenging topic of motion compensation in cone-beam CT using a new similarity metric based on visual information fidelity (VIF), which combines measures of structural similarity and image quality to describe losses associated with noise, blur, and artifacts. The research demonstrates a method to compute VIF using a deep neural network (denoted DL-VIF) without a matched, motion-free reference image. The DL-VIF demonstrated close correspondence to true VIF, and incorporation of DL-VIF as the objective function within an optimization-based, “auto-focus” motion compensation (MoCo) framework was shown to reduce motion artifacts in cone-beam CT of the head and abdomen compared to conventional metrics, such as gradient entropy.
(LINK: H. Huang et al., Reference-Free, Learning-Based Image Similarity : Application to Motion Compensation in CBCT)
Wenying Wang (PhD student at Hopkins BME) presents a model for predicting imaging performance for non-linear model-based image reconstruction (MBIR) methods, addressing challenges such as nonlinearity and shift variance that confound conventional image quality models. The research quantifies system response for MBIR using a perturbation response metric, representing the system and perturbation via a three-layer perceptron model. Taking penalized likelihood (PL) estimation with a Huber penalty as an example form of MBIR, her work demonstrates the ability to accurately predict system response for varying size, shape, and contrast of the perturbation for a broad range of patient anatomy and choice of reconstruction / regularization parameters.
(LINK: W. Wang et al., Image Properties Prediction in Nonlinear Model-based Reconstruction using a Perceptron Network)
New Deep-Learning Approach for Automatic Labeling of the Spine
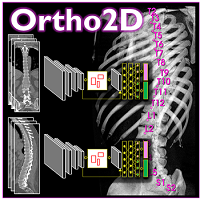 Yixuan Huang (PhD student in Biomedical Engineering) and coauthors reported a new deep-learning method called “Ortho2D” to automatically label vertebrae in CT. By detecting vertebrae separately in 2D sagittal and coronal slices, clustering, and sorting the resulting labels, Ortho2D met or exceeded the performance of previously reported methods while reducing computer memory requirements by ~50x. The method and results are detailed in their paper published in Physics in Medicine and Biology journal (LINK).
Yixuan Huang (PhD student in Biomedical Engineering) and coauthors reported a new deep-learning method called “Ortho2D” to automatically label vertebrae in CT. By detecting vertebrae separately in 2D sagittal and coronal slices, clustering, and sorting the resulting labels, Ortho2D met or exceeded the performance of previously reported methods while reducing computer memory requirements by ~50x. The method and results are detailed in their paper published in Physics in Medicine and Biology journal (LINK).
Extending preliminary studies reported two years earlier by Levine et al. (link), the Ortho2D approach tackles a memory bottleneck in conventional 3D-based vertebrae labeling frameworks by aggregating 2D detections in multiple slices viewed separately between coronal and sagittal planes. The method forms the basis for many clinical applications, including automatic labeling of large datasets for surgical data science – for example, the SpineCloud (link) model for surgical outcomes prediction – and methods for automatic surgical planning, image registration, and measurement of spinal pathology – for example, the methods to automatically measure spinal curvature (link) .
Ortho2D is built on a dual architecture of Faster R-CNN networks that work separately on coronal and sagittal slices of the input CT volume. Detections from two networks are clustered in 3D to recover the spatial information and refine results from single slices. A post-processing step enforces the anatomical order of vertebrae levels in the labeling results.
The Ortho2D framework was tested on a public dataset and compared to other recent methods. A detection F1 score of 97.1% and identification rate of 91.0% was achieved with memory consumption reduction of ~50x compared to a 3D U-Net. Additionally, because of the memory-efficient nature of Ortho2D, it can be readily extended to higher-resolution CT images, where it demonstrated a 15% increase in labeling accuracy compared to lower-resolution CT. Future work includes generalizing Ortho2D to other imaging modalities, including cone-beam CT, MRI, and 2D radiographs.
(LINK to paper) Yixuan Huang, Ali Uneri, Craig K. Jones, Xiaoxuan Zhang, Michael Daniel Ketcha, Nafi Aygun, Patrick A. Helm, and Jeffrey H. Siewerdsen. “3D vertebrae labeling in spine CT: an accurate, memory-efficient (Ortho2D) framework.” Physics in Medicine & Biology (2021). https://iopscience.iop.org/article/10.1088/1361-6560/ac07c7/meta
Deep Learning Tackles a Glaring Problem in Image-Guided Spine Surgery
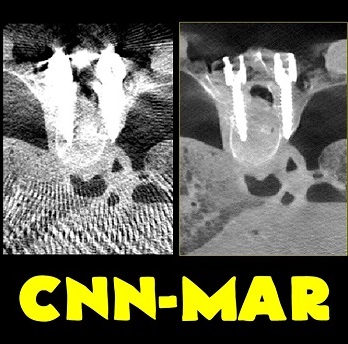 Michael Ketcha (PhD student in Biomedical Engineering) reported a new method that improves image quality, reduces radiation dose, and overcomes metal artifacts in cone-beam CT images for spine surgery. With coauthors from The I-STAR Lab and collaborators at Medtronic, the paper (link) tackles the particular challenge of imaging in the presence of metal implants – for example, pedicle screws and spinal fixation rods, where strong artifacts challenge confident visualization of the instruments and nearby anatomy.
Michael Ketcha (PhD student in Biomedical Engineering) reported a new method that improves image quality, reduces radiation dose, and overcomes metal artifacts in cone-beam CT images for spine surgery. With coauthors from The I-STAR Lab and collaborators at Medtronic, the paper (link) tackles the particular challenge of imaging in the presence of metal implants – for example, pedicle screws and spinal fixation rods, where strong artifacts challenge confident visualization of the instruments and nearby anatomy.
The method involves a dual convolutional neural network (CNN) in which one CNN operates in the sinogram domain and the other operates in the reconstructed image domain. The CNNs incorporate physical models corresponding to effects of x-ray spectra and polyenergetic x-ray absorption. The method demonstrated particularly strong performance under low-dose conditions of sparse data acquisition, where metal artifacts tend to be even more severe and compound with view sampling and quantum noise effects.
The framework was tested in phantom and cadaver studies involving real surgical implants and compared to CNN approaches operating in the image domain alone. Superior performance was observed for the dual domain CNN approach, which was better able to mitigate polyenergetic and sparse sampling effects in the sinogram domain.
Congratulations to Dr. Ketcha on this exciting final leg of his doctoral research.
(Link to Paper) Michael D. Ketcha, Michael Marrama, Andre Souza, Ali Uneri, Pengwei Wu, Xiaoxuan Zhang, Patrick A. Helm, Jeffrey H. Siewerdsen, “Sinogram + image domain neural network approach for metal artefact reduction in low-dose cone-beam computed tomography,” J. Med. Imag. 8(5), 052103 (2021), doi: 10.1117/1.JMI.8.5.052103.
Deep Learning for Medical Imaging: Uneri and Sisniega Lead a New Class at Hopkins BME
 Dr. Ali Uneri and Dr. Alejandro Sisniega (Research Faculty at Hopkins BME) led a new intersession course in 2021 on “Deep Learning for Medical Imaging,” or “DLMI” for short. The class (EN.580.106) ran in the January intersession, including fundamentals, hands-on coding assignments, and numerous examples of how deep learning is used in medical image formation and analysis.
Dr. Ali Uneri and Dr. Alejandro Sisniega (Research Faculty at Hopkins BME) led a new intersession course in 2021 on “Deep Learning for Medical Imaging,” or “DLMI” for short. The class (EN.580.106) ran in the January intersession, including fundamentals, hands-on coding assignments, and numerous examples of how deep learning is used in medical image formation and analysis.
The class presents an introduction to the advances that have occurred in machine learning and deep neural networks in particular, coupled with GPU computational capabilities and increased availability of large image datasets for training neural networks. These advances have enabled deep learning (DL) techniques for medical imaging applications that extend beyond image analysis, with increased presence of DL in the image formation process, including image preprocessing, tomographic image reconstruction, and image postprocessing informed by the requirements of specific clinical tasks.
The DLMI course introduces the foundations of deep learning methods used in medical imaging for image formation and analysis through hands-on assignments and projects in image denoising, tomographic reconstruction, artifacts correction, image segmentation, single/multi-modality registration, and feature detection/classification.
Topics covered in the course include: medical imaging modalities; machine learning; image processing; image segmentation; object detection; image reconstruction; image registration; and modality transfer.
Examples draw from numerous large datasets and challenges available online and draw from cutting-edge research led by Dr. Uneri and Dr. Sisniega at the I-STAR Lab. Advanced topics include deep learning approaches for image segmentation for automated surgical planning, 3D image registration, 3D image reconstruction, and artifact correction.
We anticipate DLMI running in upcoming intersessions and eventually in the regular semester schedule.
“Video-Drill” Puts Surgical Navigation in the Palm of your Hand: Paper by Vagdargi, Sheth, and the I-STAR Team
 A prototype system that brings all the capabilities of 3D surgical navigation into a compact backpack aboard the surgeon’s drill. The “video drill” concept was reported in a recent paper (link) first-authored by Prasad Vagdargi (PhD student in Computer Science) and Niral Sheth (Research Scientist in Biomedical Engineering) with coauthors from the I-STAR Lab and Department of Orthopaedic Surgery at Johns Hopkins University. The system could help improve the accuracy and safety of percutaneous fracture fixation while reducing radiation dose in surgeries guided by x-ray fluoroscopy.
A prototype system that brings all the capabilities of 3D surgical navigation into a compact backpack aboard the surgeon’s drill. The “video drill” concept was reported in a recent paper (link) first-authored by Prasad Vagdargi (PhD student in Computer Science) and Niral Sheth (Research Scientist in Biomedical Engineering) with coauthors from the I-STAR Lab and Department of Orthopaedic Surgery at Johns Hopkins University. The system could help improve the accuracy and safety of percutaneous fracture fixation while reducing radiation dose in surgeries guided by x-ray fluoroscopy.
In the initial prototype (“Mark-1”), a video camera was mounted onboard a surgical drill and calibrated to the drill axis. A set of novel marker disks that can be seen in both video and x-ray fluoroscopy are placed about the surgical field to co-register the video and fluoroscopic scenes. The drill trajectory can thus be overlaid in fluoroscopic images to ensure that the surgeon’s path is within desired bone corridors. By registering the fluoroscopic scene to preoperative CT, the drill trajectory can be viewed relative to CT (or cone-beam CT), brining all the capabilities of 3D surgical navigation into the surgeon’s hand. The co-registration of video, fluoroscopy, and CT is robust to motion of the patient or disk markers, because the registration is updated with each fluoroscopy frame.
Initial studies demonstrated target registration error (TRE) of 0.9 mm and 2.0 degrees when registered to biplane fluoroscopy and 3.4 mm and 2.7 degree when registered to a single view. Registration was robust with as few as four disk markers and was sufficient to maintain drill trajectories within bone corridors for all cases studied in this initial work.
First experience with a second prototype (“Mark-2”) was reported at the SPIE Medical Imaging conference in Feburary, 2021, by Niral Sheth and coauthors. The Mark-2 featured smaller disk markers, a more compact and accurate video camera mount, and further improved TRE. The initial studies with the Mark-2 can be found in the SPIE Proceedings (link).
The video-drill concept was developed to assist with challenging K-wire placement in scenarios such as pelvic trauma surgery and long-bone fixation. Workflow is compatible with fluoroscopically guided trauma surgery and could overcome the cost and workflow bottlenecks of conventional 3D navigation systems.
(Link to Paper)Prasad Vagdargi, Niral M. Sheth, Alejandro Sisniega, Ali Uneri, Tharindu S. De Silva, Greg M. Osgood, Jeffrey H. Siewerdsen, “Drill-mounted video guidance for orthopaedic trauma surgery,” J. of Medical Imaging, 8(1), 015002 (2021). https://doi.org/10.1117/12.2581774
Long-Length Imaging and Registration for Spine Surgery: New Paper by Esme Zhang
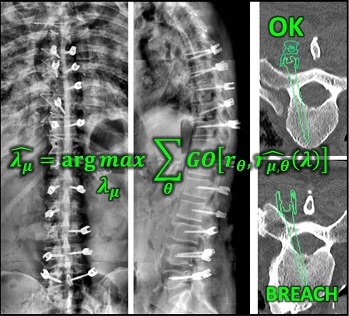 A new paper by Xiaoxuan (Esme) Zhang (PhD student in Biomedical Engineering at Johns Hopkins University) investigates the capability to form long-length tomosynthesis (“LongFilm”) images using a new system of multi-slot collimators on the O-Arm (Medtronic). This paper shows imaging protocols and image reconstruction techniques for the long-length imaging system along with quantitative evaluation of image quality, image registration, and radiation dose. Such a system could open new capabilities for surgical guidance and evaluation of long constructs in sine surgery.
A new paper by Xiaoxuan (Esme) Zhang (PhD student in Biomedical Engineering at Johns Hopkins University) investigates the capability to form long-length tomosynthesis (“LongFilm”) images using a new system of multi-slot collimators on the O-Arm (Medtronic). This paper shows imaging protocols and image reconstruction techniques for the long-length imaging system along with quantitative evaluation of image quality, image registration, and radiation dose. Such a system could open new capabilities for surgical guidance and evaluation of long constructs in sine surgery.
A multi-slot collimator with tilted apertures was integrated into an O-arm prototype for long-length imaging. The multi-slot projective geometry gives a useful view disparity in projection images allowing tomosynthesis “slot reconstructions” using a weighted-backprojection method. The radiation dose for long-length imaging was measured, and the utility of long-length, intraoperative tomosynthesis was evaluated in phantom and cadaver studies.
Leveraging the depth resolution provided by multi-slot parallax views, an algorithm for 3D-2D registration of surgical devices was implemented to solve the 3D pose of instruments relative to preoperative CT. Registration performance using was evaluated and compared to the accuracy achieved using standard biplane radiographs.
Longitudinal coverage of ~50–64 cm was achieved with a long-length slot scan, providing a field-of-view up to (40 × 64) cm2. The dose-area product (reference point air kerma × x-ray field area) was equivalent to ~2.5 s of fluoroscopy and comparable to other long-length imaging systems. Long-length scanning produced high-resolution tomosynthesis reconstructions, covering ~12–16 vertebral levels. 3D image registration using dual-plane slot reconstructions achieved median target registration error (TRE) of 1.2 mm and 0.6° in cadaver studies. 3D registration using single-plane slot reconstructions leveraged the ~7–14° angular separation between slots to achieve median TRE ~2 mm and < 2° from a single scan.
Long-length imaging with a multi-slot collimator on the O-arm provided intraoperative visualization of long spine segments, facilitating target localization, assessment of global spinal alignment, and evaluation of long surgical constructs. 3D-2D registration to long-length tomosynthesis reconstructions yielded a promising means of guidance and verification with accuracy exceeding that of 3D-2D registration to conventional radiographs.
(Link to paper) Xiaoxuan Zhang, Ali Uneri, Pengwei Wu, Michael Daniel Ketcha, Craig Jones, Yixuan Huang, Sheng-fu L Lo, Patrick A Helm, and Jeffrey H Siewerdse “Long-length tomosynthesis and 3D-2D registration for intraoperative assessment of spine instrumentation” Institute of Physics and Engineering in Medicine, 2020 https://iopscience.iop.org/article/10.1088/1361-6560/abde96/meta
Accelerating 3D Image Reconstruction: Paper by Dr. Sisniega Breaks Conventional Speed Limits
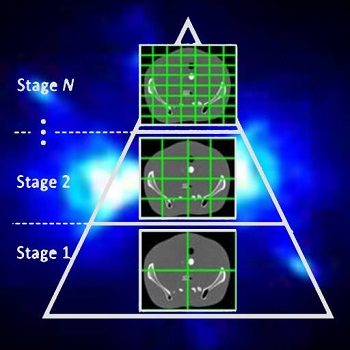 Model-based iterative reconstruction (MBIR) for cone-beam CT (CBCT) offers better noise-resolution tradeoffs and low-dose limits than conventional analytical methods. However, the high computational burden of MBIR poses a drawback to runtime and practical, clinical application.
Model-based iterative reconstruction (MBIR) for cone-beam CT (CBCT) offers better noise-resolution tradeoffs and low-dose limits than conventional analytical methods. However, the high computational burden of MBIR poses a drawback to runtime and practical, clinical application.
A new paper by Dr .Alejandro Sisniega describes a comprehensive framework for accelerating MBIR in the form of penalized weighted least squares (PWLS) optimized with ordered subsets via separable quadratic surrogates. The optimization follows a hierarchical pyramid of stages varying in voxel size and other optimization parameters. Transition between stages is controlled with a smart convergence criterion based on the difference in noise correlation (specifically, the mid-band noise power spectrum, NPS) between the current iteration and that predicted for the converged image.
Another important feature of the acceleration framework is a stochastic backprojector (SBP) that introduces a random perturbation to the sampling position of each voxel for each ray in the reconstruction within voxel-based backprojection. Doing so breaks deterministic sampling patterns that conventionally causes artifacts when combined with an unmatched Siddon forward projector. Furthermore, a multi-resolution reconstruction strategy was implemented to provide support for objects partially outside the field of view. Acceleration from ordered subsets was combined with momentum accumulation stabilized with an adaptive restart technique that automatically resets the accumulated momentum when it diverges from the current iteration update.
The acceleration algorithm was tested with CBCT scans of an abdomen phantom imaged on the I-STAR Lab x-ray bench and with a clinical CBCT C-arm (Artis Zeego, Siemens Healthineers, Forchheim, Germany). Image fidelity was assessed in terms of the structural similarity index (SSIM) computed with a fully converged, conventional reconstruction.
The use of simple forward and backprojectors resulted in 9.3x acceleration. Including momentum accumulation in the iterative optimization provided an extra ~3.5x acceleration with stable convergence for 6 to 30 subsets. The NPS convergence criterion resulted in faster convergence, achieving similar SSIM with 1.5x lower runtime than the single-stage optimization.
Overall, the acceleration framework provided accurate 3D image reconstruction in as little as 27 s (SSIM = 0.94) for soft-tissue image reconstructions. The acceleration framework provided reconstruction time compatible with many clinical applications with fairly common, single GPU architectures.
(Link to paper) A. Sisniega, JW Stayman, S Capostagno, CR Weiss, T Ehtiati, and JH Siewerdsen, “Accelerated 3D image reconstruction with a morphological pyramid and noise-power convergence criterion” Institute of Physics and Engineering in Medicine, 2020 https://iopscience.iop.org/article/10.1088/1361-6560/abde97/meta
SPIE Medical Imaging 2021 – Digital Forum – Presentations from the I-STAR Lab
 The SPIE Medical Imaging 2021 symposium has gone digital– a Digital Forum combining live events with pre-recorded presentations and communication via slack.
The SPIE Medical Imaging 2021 symposium has gone digital– a Digital Forum combining live events with pre-recorded presentations and communication via slack.
Presentations from the I-STAR Lab include new work in 3D image reconstruction, image registration, robotic assistance, surgical guidance, and more. Check out some of the abstracts and presentations at the following links for both the Physics of Medical Imaging and the Image-Guided Procedures, Robotic Interventions, and Modeling conferences as well as the Digital Pathology and Computational Pathology conference::
PHYSICS OF MEDICAL IMAGING:
Session 1: CT: Optimization and Image Quality Gang et al. End-to-end modeling for predicting and estimating radiomics: application to gray level co-occurrence matrices in CT, SPIE Physics of Medical Imaging (LINK).
Session 3: Machine Learning in Imaging Physics Wang et al. A CT denoising neural network with image properties parameterization and control, SPIE Physics of Medical Imaging (LINK).
Session 4: Phantoms and Lesion Insertion Pan et al. Generative adversarial networks and radiomics supervision for lung lesion synthesis, SPIE Physics of Medical Imaging (LINK).
Session 5: Image Guided Intervention Sisniega et al. Deformable image-based motion compensation for interventional cone-beam CT with learned autofocus metrics, SPIE Physics of Medical Imaging (LINK).
Wu et al., Cone-beam CT for neurosurgical guidance: high-fidelity artifacts correction for soft-tissue contrast resolution, SPIE Physics of Medical Imaging (LINK).
Session 8: Spectral CT Liu et al., Quantitative dual-energy imaging in the presence of metal implants using locally constrained model-based decomposition, SPIE Physics of Medical Imaging (LINK).
Session 11: CT: Reconstruction Tivnan et al., Manifold reconstruction of differences: a model-based iterative statistical estimation algorithm with a data-driven prior, SPIE Physics of Medical Imaging (LINK).
Session 13: X-ray Imaging: Dosimetry, Scatter, and Motion Zhao et al., Image-domain cardiac motion compensation in multidirectional digital chest tomosynthesis, SPIE Physics of Medical Imaging (LINK).
Session 14: Dual-energy: Optimization and Clinical Application Zhao et al., Effects of x-ray scatter in quantitative dual-energy imaging using dual-layer flat panel detectors, SPIE Physics of Medical Imaging (LINK).
Session 19: Machine Learning Applied to Imaging Physics – Posters Li et al., Mitigating unknown biases in CT data using machine learning, SPIE Physics of Medical Imaging (LINK).
IMAGE-GUIDED PROCEDURES, ROBOTIC INTERVENTIONS, AND MODELING
Session 1: Robot-Assisted Interventional Platforms and Devices Sheth et al. Pre-clinical evaluation of a video-based drill guidance system for orthopaedic trauma surgery, SPIE Image-Guided Procedures, Robotic Interventions, and Modeling (LINK).
Session 2: Image-guided Video-based Applications Vagdargi et al. Robot-assisted ventriculoscopic 3D reconstruction for guidance of deep-brain stimulation surgery, SPIE Image-Guided Procedures, Robotic Interventions, and Modeling (LINK).
Session 11: Data Driven Deformable Image Registration for IGT Han et al. Deformable MR-CT image registration using an unsupervised end-to-end synthesis and registration network for endoscopic neurosurgery, SPIE Image-Guided Procedures, Robotic Interventions, and Modeling (LINK).
Uneri et al. Data-driven deformable 3D-2D registration for guiding neuroelectrode placement in deep brain stimulation, SPIE Image-Guided Procedures, Robotic Interventions, and Modeling (LINK).
Session 12: Novel Applications in Image-guided Therapy Vijayan et al. Fluoroscopic guidance of a surgical robot: pre-clinical evaluation in pelvic guidewire placement, SPIE Image-Guided Procedures, Robotic Interventions, and Modeling (LINK).
Session 13: Image-Guided Procedures, Robotic Interventions, and Modeling – Posters Bataeva et al. Intraoperative guidance of orthopaedic instruments using 3D correspondence of 2D object instance segmentations, SPIE Image-Guided Procedures, Robotic Interventions, and Modeling (LINK).
DIGITAL AND COMPUTATIONAL PATHOLOGY
Session 6: Posters Poinapen et al. Three-dimensional shape and topology analysis of tissue-cleared tumor samples, SPIE Digital and Computational Pathology (LINK).
New Multi-Institutional Project with Dr. Zbijewski on Forensic Analysis of Bone Morphology using CT
 Dr. Wojciech Zbijewski (Assistant Professor in Biomedical Engineering and PI in the I-STAR Lab) is among the Co-Principal Investigators in a new multi-institutional project that uses high-resolution CT and statistical modeling of bone shape and microstructure for forensic analysis. Sponsored by the U.S. Department of Justice, the new project tackles the challenge of estimating body mass and/or BMI in the skeletal remains of unidentified individuals.
Dr. Wojciech Zbijewski (Assistant Professor in Biomedical Engineering and PI in the I-STAR Lab) is among the Co-Principal Investigators in a new multi-institutional project that uses high-resolution CT and statistical modeling of bone shape and microstructure for forensic analysis. Sponsored by the U.S. Department of Justice, the new project tackles the challenge of estimating body mass and/or BMI in the skeletal remains of unidentified individuals.
Three research groups are involved in the effort: Dr. Zbijewski and team at Johns Hopkins Biomedical Engineering to work on CT imaging and shape and texture analysis; Dr. Adam Sylvester at the Johns Hopkins Center for Functional Anatomy and Evolution, an expert in statistical modeling of skeletal morphology; and Dr. Daniel Wescott and Dr. Deborah Cunnigham at Texas State University, the project lead site with resources and technical expertise related to large repositories of skeletal samples.
In identifying individuals based on skeletal remains, forensic anthropologists are faced with numerous challenges, including the need to estimate body mass and/or BMI. Particularly as the prevalence of obesity increases, the ability to assess BMI from skeletal remains could be of major benefit in establishing a biological profile in medicolegal death investigations.
The research aims to develop a reliable means of estimating BMI using CT images of skeletal remains combined with statistical shape and texture analysis. The analysis includes quantitative imaging of joint size, trabecular bone structure, diaphyseal cross-sectional properties, and whole-bone shape properties and establishes reliable correspondence between such features and body mass and/or BMI. By combining macro-scale shape analysis with micro-scale texture analysis, the researchers aim to establish whether such correspondences exist and the accuracy with which BMI can be accurately determined from skeletal remains. Preliminary studies suggest that the link may be evident in weight-bearing skeletal elements, such as the calcaneus, talus, tibia, femur, and the 4th lumbar vertebra. The project aims to establish reliable CT-based markers of BMI and translate the research findings into a software package for law enforcement to facilitate forensic analysis of skeletal remains.
Congratulations to Dr. Zbijewski and team on this exciting new project.
Paper by Runze Han et al. Solves Multi-Body Registration for Image-Guided Trauma Surgery
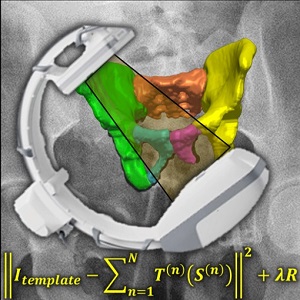 Fracture reduction is a challenging surgical procedure that requires accurate positioning of multiple bone fragments to proper locations. Failure to restore alignment can lead to poor outcomes and the need for revision surgery. To improve the accuracy of fracture reduction surgery, Runze Han (PhD student at Hopkins BME) and I-STAR Lab coauthors have reported a method (link) that automatically solves the proper pose and orientation of multiple bone fragments in preoperative CT and provides intraoperative visualization and guidance of the reduction. Because the method operates on conventional 2D fluoroscopy (solving the multi-body 3D-2D registration to preoperative CT), the method may be broadly applicable in routine clinical workflow in orthopaedic trauma surgery.
Fracture reduction is a challenging surgical procedure that requires accurate positioning of multiple bone fragments to proper locations. Failure to restore alignment can lead to poor outcomes and the need for revision surgery. To improve the accuracy of fracture reduction surgery, Runze Han (PhD student at Hopkins BME) and I-STAR Lab coauthors have reported a method (link) that automatically solves the proper pose and orientation of multiple bone fragments in preoperative CT and provides intraoperative visualization and guidance of the reduction. Because the method operates on conventional 2D fluoroscopy (solving the multi-body 3D-2D registration to preoperative CT), the method may be broadly applicable in routine clinical workflow in orthopaedic trauma surgery.
The paper published in Medical Image Analysis (MedIA) details the multi-body registration algorithm along with phantom and cadaver experiments as well as first clinical studies. In preoperative CT, the system automatically determines a reduction plan by solving a complex multi-to-one registration to align multiple bone fragments to an “adaptive template” – a statistical shape and pose model that adapts to patient-specific anatomy. During surgery, the method registers bone fragments in 2D x-ray fluoroscopy using multi-body 3D-2D registration. The system provides both 2D guidance (by overlaying the desired pose of fragments on live fluoroscopy) as well as 3D navigation (showing the current and desired pose of fragments relative to preoperative CT). Because the system operates on image data directly, it requires no additional tracking or navigation devices, using C-arm fluoroscopy that is already in common use.
Experiments reported in the paper included digital simulation, cadaver studies, and retrospective clinical studies involving a broad range of complex pelvic fracture patterns. The results demonstrated significant improvement in the accuracy of reduction planning compared to the conventional method of referencing the (unfractured) contralateral pelvis as a guide to reduction. The method demonstrated improved accuracy (median residual error ~2.2 mm and ~2.2°, compared to ~5.3 mm and ~7.4° for the conventional approach). The method is also applicable to bilateral fractures, where a contralateral reference is not available.
The work was published in Medical Image Analysis: R. Han, A. Uneri, R.C. Vijayan, P. Wu, P. Vagdargi, N. Sheth, S. Vogt, G. Kleinszig, G.M. Osgood, J.H. Siewerdsen, “Fracture Reduction Planning and Guidance in Orthopaedic Trauma Surgery via Multi-Body Image Registration,” Medical Image Analysis, 2020. https://doi.org/10.1016/j.media.2020.101917
Fighting COVID-19: Ultraviolet light (UV-C) for decontamination of CT scanners
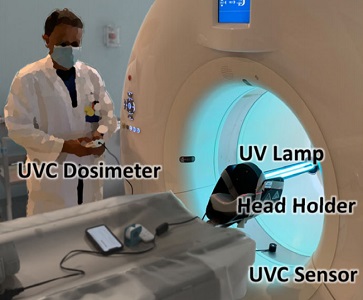 Hopkins BME and Radiology teamed up to find a method to decontaminate CT scanners against viruses – an especially important topic amid the COVID-19 pandemic. While CT is a vital tool in imaging lung disease, decontamination of the scanner by manual wipe-down typically takes around 30 minutes, limiting its use during periods of high patient loads. Hopkins BME and Radiology teamed up to find a way to accomplish disinfection of the CT scanner bore within just a few minutes.
Hopkins BME and Radiology teamed up to find a method to decontaminate CT scanners against viruses – an especially important topic amid the COVID-19 pandemic. While CT is a vital tool in imaging lung disease, decontamination of the scanner by manual wipe-down typically takes around 30 minutes, limiting its use during periods of high patient loads. Hopkins BME and Radiology teamed up to find a way to accomplish disinfection of the CT scanner bore within just a few minutes.
The work was reported in an article by Dr. Mahadevappa Mahesh (Radiology) and Dr. Jeffrey H. Siewerdsen (The I-STAR Lab) published in the Journal of Applied Clinical Medical Physics (JACMP). Mahesh and Siewerdsen investigated the feasibility and practicality of ultraviolet (UV-C) germicidal irradiation of the inner bore of a CT scanner gantry as a means of viral decontamination.
Using a UV-C lamp and dosimeter to measure irradiance throughout the inner bore of a CT scanner gantry, they measured the time and UV-C dose to achieve a >6-log viral kill (10−6 survival fraction). Irradiance at the scan plane (z=0 cm) of the CT scanner was 580.9 μW/cm2, reducing to~350 μW/cm2 at z=20 cm toward the front or back of the gantry. The angular distribution of irradiation was uniform within 10% coefficient of variation. A conservative estimate suggests >6-log kill (survival fraction ≤ 10−6) of viral RNA within 20 cm of the scan plane with an irradiation time of 120 s from cold start. More conservatively, running the lamp for 180 s (3 min) or 300 s (5 min)from cold start is estimated to yield a survival fraction << 10−7survival fraction within20 cm of the scan plane.
Mahesh and Siewerdsen conclude that use of UV-C irradiation could augment manual wipe-down procedures, improve safety for CT technologists or house keeping staff, and could potentially reduce turnover time between scanning sessions.
The journal paper by Mahadevappa Mahesh and Jeffrey H. Siewerdsen. Journal of Applied Clinical Medical Physics. September 20th, 2020. DOI: 10.1002/acm2.13067
A video abstract for the paper can be viewed here
3D Image Reconstruction with “Known Components” Improves Dual-Energy Cone-Beam CT – New Paper by Stephen Liu et al.
Dual-energy (DE) decomposition has been adopted in orthopedic imaging to measure bone composition and visualize intraarticular contrast enhancement. One of the potential applications involves monitoring of callus mineralization for longitudinal assessment of fracture healing. However, fracture repair usually involves internal fixation hardware that can generate significant artifacts in reconstructed images.
 A paper by Stephen Liu at the I-STAR Lab at Hopkins BME addresses this challenge. The authors have developed a novel approach that augments their previous model-based material decomposition algorithm (MBMD) with the Known-Component (KC) reconstruction framework. Compared to conventional approaches, MBMD enables direct projection-based decomposition from systems where the two energy channels are acquired using non-coinciding rays. To mitigate metal artifacts in MBMD, the KC framework incorporates a digital model of the surgical hardware to inform the decomposition about the location and attenuation properties of the metal components.
A paper by Stephen Liu at the I-STAR Lab at Hopkins BME addresses this challenge. The authors have developed a novel approach that augments their previous model-based material decomposition algorithm (MBMD) with the Known-Component (KC) reconstruction framework. Compared to conventional approaches, MBMD enables direct projection-based decomposition from systems where the two energy channels are acquired using non-coinciding rays. To mitigate metal artifacts in MBMD, the KC framework incorporates a digital model of the surgical hardware to inform the decomposition about the location and attenuation properties of the metal components.
The algorithm was applied to simulated DE data representative of a dedicated extremity cone-beam CT (CBCT) employing an x-ray unit with three vertically arranged sources. This system is an attractive platform for fracture follow-up because it enables weight-bearing
3D imaging to assess the stability of the healing bone. The scanner generates DE data with non-coinciding high- and low-energy projection rays when the central source is operated at high tube potential and the peripheral sources at low potential. The algorithm was validated using a digital extremity phantom containing varying concentrations of Ca-water mixtures and Ti implants. Decomposition accuracy was compared to MBMD without the KC model.
The method suppressed metal artifacts and yielded estimated Ca concentrations that approached the reconstructions of an implant-free phantom for most mixture regions. In the vicinity of simple components, the errors of Ca density estimates obtained by incorporating KC in MBMD were ~1.5 – 5x lower than the errors of conventional MBMD; for cases with complex implants, the errors were ~3 – 5x lower.
In conclusion, the proposed method can achieve accurate bone mineral density measurements in the presence of metal implants using non-coinciding DE projections acquired on a multisource CBCT suitable for weight-bearing assessment of fractures.
Stephen Z Liu, Qian Cao, Matthew Tivnan, Steven W Tilley II, J Webster Stayman, Wojciech Zbijewski, Jeffrey H Siewerdsen Model-based dual-energy tomographic image reconstruction of objects containing known metal components. Phys Med Biol. 2020 Oct 28. doi: 10.1088/1361-6560/abc5a9.
Deformable motion compensation for interventional cone-beam CT
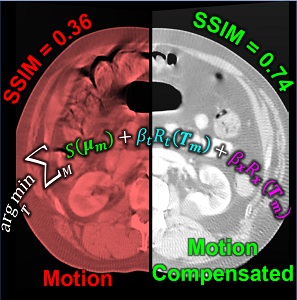 Image-guided interventions in the abdomen require clear visualization of soft-tissue target structures and adjacent normal anatomy. Unfortunately, cone-beam CT (CBCT) involves fairly long scan time (5-30 sec), and image quality can be confounded by motion artifacts arising from complex, non-periodic, deformable organ motion. In recent years, the influence of even small amounts of motion during CBCT scanning has come to be recognized as one of the major impediments to soft-tissue image quality. Research at the I-STAR Lab has developed new methods for motion compensation, including rigid motion appropriate to the cranium and – more recently – deformable motion compensation to address these challenges to image quality and improve CBCT guidance.
Image-guided interventions in the abdomen require clear visualization of soft-tissue target structures and adjacent normal anatomy. Unfortunately, cone-beam CT (CBCT) involves fairly long scan time (5-30 sec), and image quality can be confounded by motion artifacts arising from complex, non-periodic, deformable organ motion. In recent years, the influence of even small amounts of motion during CBCT scanning has come to be recognized as one of the major impediments to soft-tissue image quality. Research at the I-STAR Lab has developed new methods for motion compensation, including rigid motion appropriate to the cranium and – more recently – deformable motion compensation to address these challenges to image quality and improve CBCT guidance.
A paper by Sarah Capostagno et al. reports a method for deformable motion compensation that operates on a set of small regions of interest to solve individual (rigid) motion trajectories and interpolate the results between regions to produce an estimate of deformable motion. The method solves a complex optimization via an image-based cost function consisting of an autofocus objective (gradient entropy) and spatiotemporal regularization. Motion trajectories are estimated using an iterative optimization algorithm (CMA-ES) and used to interpolate a 4D spatiotemporal motion vector field. The motion-compensated image is reconstructed using a modified filtered backprojection approach.
The experiments included digital simulation, phantom studies, and cadaver studies involving a broad range of complex realistic motion. The results demonstrated increases in structural similarity index (SSIM – a measurement of image accuracy) of ~20% – 92% over the range of motion investigated. The visibility of soft-tissue structures (e.g., liver-fat boundaries) as well as high-contrast structures (e.g., bone or interventional devices) were markedly improved with the motion compensation method. Research stemming from this work translates the method to first clinical studies in interventional radiology for trans-arterial chemo-embolization (TACE) of the liver.
This study was published by Physics in Medicine & Biology: Sarah Capostagno, Alejandro Sisniega, Joseph W Stayman, Tina Ehtiati, Clifford R Weiss, and Jeffrey H Siewerdsen, “Deformable motion compensation for interventional cone-beam CT”, Phys. Med. Biol. August 2020 https://doi.org/10.1088/1361-6560/abb16e
Congratulations, Dr. Michael Ketcha! PhD Dissertation on Medical Image Registration

Michael Ketcha successfully defended his PhD dissertation at Hopkins BME — Kudos and congratulations, Dr. Ketcha!
Michael tackled questions ranging from the theoretical underpinnings of image registration performance to numerous practical implications for development of new registration algorithms and application to image-guided interventions.
Key to Michael’s work was a theoretical framework relating registration performance to factors of image quality. From first principles of statistical estimation, Michael related image quality factors such as the noise-power spectrum (NPS) and modulation transfer function (MTF) to the Cramer-Rao lower bound (CRLB) in registering two images. In so doing, his work sheds light on the fundamental limits of various similarity metrics (such as normalized cross correlation, mutual information, and gradient-based similarity), the dose levels required (in CT and cone-beam CT) to achieve a given level of registration accuracy, and optimal blur applied in post-processing.
For the task of image registration, Michael’s work shows striking parallels to well established models from statistical decision theory for tasks of image detection / discrimination. Specifically, he showed how the Fisher Information Matrix for image registration is related to the image NPS and MTF in a manner directly analogous to task-based detectability index. Moreover, Michael showed how soft-tissue deformation can act as a “noise” source for the task of rigid image registration in a manner directly analogous to how anatomical “clutter” presents a noise source to tasks of detection. Such models of task-based detectability have been vital to advances in diagnostic imaging (e.g., optimization of new imaging systems and identification of low-dose limits), and Michael’s work demonstrates a theoretical foundation for similar advances in image registration and image-guided interventions.
Rounding out the thesis were important related topics of deformable 3D-2D image registration for image-guided spine surgery and neural network methods for MR-CT registration in image-guided neurosurgery.
Example journal publications from Michael and coauthors along the way include:
- Ketcha et al., “Effects of image quality on the fundamental limits…” IEEE Trans Med Imag. 36(10) (2017) (LINK)
- Ketcha et al., “A statistical model for rigid image registration…” IEEE Trans Med Imag. 38(9) (2019) (LINK)
- Ketcha et al., “Multi-stage 3D-2D registration…” Phys Med Biol 62(11) (2017) (LINK)
- Ketcha et al., “Learning-based deformable image registration…” J Med Imag. 6(4) (2019) (LINK)
Michael joins the ranks of tremendous alumni from Hopkins BME, where he did both his undergraduate and doctoral work. Along the way, he co-directed the Hopkins Imaging Conference, co-founded the Hiking Club, worked with a successful startup on ultrasound imaging, completed a PhD research internship at Medtronic, and was recognized as one of the 2020 Siebel Scholars.
CONGRATULATIONS, Dr. Ketcha!
Paper by Pengwei Wu Reports C-arm Orbits for Metal Artifact Avoidance (MAA) in Cone-Beam CT
 Metal artifacts present a challenge to cone-beam CT (CBCT) for image-guided surgery by obscuring visualization of metal instruments and adjacent anatomy. To reduce the severity of metal artifacts, Pengwei Wu (PhD student at Hopkins BME) struck upon a method to determine orbits of the C-arm (i.e., the path followed by the x-ray source and detector about the patient) to reduce metal-induced biases in the projection data. The method and results are reported in a recent paper.
Metal artifacts present a challenge to cone-beam CT (CBCT) for image-guided surgery by obscuring visualization of metal instruments and adjacent anatomy. To reduce the severity of metal artifacts, Pengwei Wu (PhD student at Hopkins BME) struck upon a method to determine orbits of the C-arm (i.e., the path followed by the x-ray source and detector about the patient) to reduce metal-induced biases in the projection data. The method and results are reported in a recent paper.
Pengwei and colleagues at the I-STAR Lab developed the metal artifact avoidance (MAA) method in a practical form that addresses many of the challenges of 3D imaging in the presence of metal instrumentation: (1) while compatible with systems that can perform a complex, non-circular orbit (e.g., robotic C-arms), it can also be implemented on relatively simple mobile C-arms that may only allow scanning with a simple gantry tilt; (2) the method does not require exact prior information on the patient or metal implants; (3) the method is consistent with metal artifact reduction (MAR) post-processing that could further improve image quality; and (4) while compatible with advanced, polyenergetic, model-based image reconstruction, the method in its simplest form showed substantial reduction in (avoidance of) metal artifacts for basic filtered backprojection (FBP).
The MAA method forms a coarse localization of metal objects in the FOV from two or more low-dose scout projection views and a U-Net segmentation. Based on this coarse 3D localization of metal objects, a simple cost function is computed related to the magnitude of metal-induced x-ray spectral shift (“beam hardening”). By analyzing this simple cost function for all combinations of gantry rotation and tilt, circular or non-circular orbits are identified that avoid beam hardening effects in the scan data.
The method was evaluated in a series of experiments, including simulation, phantom, and cadaver studies in the context of image-guided spine surgery, including realistic distributions of various types of metallic spine screws. The MAA method accurately predicted tilted circular and non-circular orbits that reduced the magnitude of metal artifacts, yielding 3D image reconstructions with 46-70% reduction of RMSE in 3D image reconstructions and 20-45% reduction of “blooming” artifacts. Non-circular orbits defined by MAA achieved a further ~46% reduction in RMSE.
The MAA method and experiments were published in Physics in Medicine & Biology: P. Wu, N. Sheth, A. Sisniega, A. Uneri, R. Han, R. Vijayan, P. Vagdargi, B. Kreher, H. Kunze, G. Kleinszig, S. Vogt, S.-F. Lo, N. Theodore, and J. H. Siewerdsen, “C-arm orbits for metal artifact avoidance (MAA) in cone-beam CT,” Phys. Med. Biol. May 2020. https://doi.org/10.1088/1361-6560/ab9454
Congratulations, Dr. Sarah Capostagno! PhD Dissertation on Complex Motion Correction and Task-Driven 3D Imaging
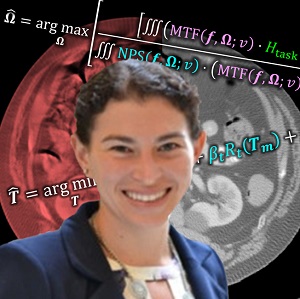 Congratulations to Dr. Sarah Capostagno, who successfully defended her PhD dissertation entitled Image-guided Interventions Using Cone-Beam CT: Improving Image Quality With Motion Compensation And Task-based Modeling.
Congratulations to Dr. Sarah Capostagno, who successfully defended her PhD dissertation entitled Image-guided Interventions Using Cone-Beam CT: Improving Image Quality With Motion Compensation And Task-based Modeling.
Sarah tackled two major areas of optimization-based 3D imaging in her doctoral studies. The first involved methods for rigid and deformable motion compensation in cone-beam CT (CBCT). The rigid motion compensation method used 3D-2D registration of scan data to a prior 3D image. Application to CBCT of the head yielding accurate correction even for large motion amplitude (>50 mm) without additional fiducials or optical tracking. The work also demonstrated a method to improve CBCT image quality even in motion-free cases by correcting small errors in geometric calibration. Tackling the even greater challenge of complex, deformable motion, Sarah developed a “3D autofocus” method that operates without prior images by maximizing a sharpness criterion in local regions throughout the image volume to derive complex, non-rigid motion trajectories. She developed the method through a series of simulation, phantom, cadaver, and clinical studies that demonstrated strong reduction in motion artifacts and substantial improvement in soft-tissue visibility in challenging scenarios of large, non-periodic, deformable motion – for example, the liver.
The second major area of Sarah’s work involved task-driven 3D imaging, whereby any particular aspect of image acquisition or reconstruction can be optimized based on the structures of interest – i.e., optimized according to the task. Sarah’s work focused on optimization of the trajectory of the x-ray source and detector. Whereas conventional CBCT acquisition involves a simple circular orbit, Sarah’s work yielded a method to define orbits that maximize the detectability index for a particular patient (accounting for patient-specific size, shape, and attenuation) and imaging task (i.e., the location, contrast, and spatial-frequencies associated with detection or discrimination of a particular structure of interest). She developed the work in simulation and phantom studies and translated the work to the first task-driven trajectories conducted on a robotic C-arm (Artis Zeego). The method was shown to provide particular benefit in challenging imaging scenarios involving highly attenuating objects in the field of view, such as implants or surgical instrumentation.
Dr. Capostagno’s work on motion compensation can be found in the following papers:
- Ouadah et al., Self-calibration of cone-beam CT geometry using 3D–2D image registration, Physics in Medicine & Biology 61 (7), 2613 (link)
- Ouadah et al., Correction of patient motion in cone-beam CT using 3D–2D registration, Physics in Medicine & Biology 62 (23), 8813 (link)
- Capostagno et al., Image-based deformable motion compensation in cone-beam CT: translation to clinical studies in interventional body radiology, Medical Imaging 2020: Image-Guided Procedures, Robotic Interventions, and Modeling 11315: 113150B (link)
- Capostagno et al., Image-based deformable motion compensation for interventional cone-beam CT, Phys Med Biol (submitted; under review, May 2020).
And her work on task-driven 3D imaging can be found in:
- Stayman* and Capostagno* et al., Task-driven source–detector trajectories in cone-beam computed tomography: I. Theory and methods, Journal of Medical Imaging 6 (2), 025002 (link)
- Capostagno* and Stayman* et al., Task-driven source–detector trajectories in cone-beam computed tomography: II. Application to neuroradiology, Journal of Medical Imaging 6 (2), 025004 (link)
CONGRATULATIONS!!! to Dr. Sarah Capostagno for outstanding insight on such challenging problems – and for her commitment to seeing imaging research forward to genuine clinical impact.
Fighting COVID-19 with Physics, Engineering, and Imaging
 The COVID-19 pandemic represents a healthcare emergency that is unprecedented in scale and lethality since the Spanish Flu of 1917. A century ago, the Welch Labs at Johns Hopkins University were a beacon of science in medicine in North America, and the School of Public Health at Hopkins was the first of its kind – its genesis just in time to meet the threat. The public health countermeasures and vaccine development that followed were instrumental in prevailing against the most severe outbreak in the western world since the bubonic plague. Read more on this tremendous testament to science in medicine in John M. Barry’s book, The Great Influenza.
The COVID-19 pandemic represents a healthcare emergency that is unprecedented in scale and lethality since the Spanish Flu of 1917. A century ago, the Welch Labs at Johns Hopkins University were a beacon of science in medicine in North America, and the School of Public Health at Hopkins was the first of its kind – its genesis just in time to meet the threat. The public health countermeasures and vaccine development that followed were instrumental in prevailing against the most severe outbreak in the western world since the bubonic plague. Read more on this tremendous testament to science in medicine in John M. Barry’s book, The Great Influenza.
The call to arms in response to COVID-19 is being answered similarly. At Hopkins BME, faculty and students are bringing the breadth and depth of biomedical engineering expertise to answer the call – including Dr. Winston Timp leading the Viral Genetics arm of the JHU COVID-19 Research Response Program, Dr. Elizabeth Logsdon and Dr. Warren Grayson working with BME students, the WSE Manufacturing Facility, and the Johns Hopkins Command Center for 3D-printing of face-shields, and much more.
Joining the fight are researchers at the I-STAR Lab and the Carnegie Center for Surgical Innovation, working closely with clinical collaborators to tackle immediate and long-term challenges:
- Reprocessing / Decontamination of N95 Masks. To meet the immediate need for reprocessing of PPE – especially N95 masks – two Surgineering students (Kevin Gilboy and Matt Tivnan) are developing a system for decontamination of PPE using ultraviolet (UV-C) irradiation. Working closely with collaborators (Gina Adrales, Dan Warren, and Ivan George) in the Department of Surgery in coordination with Hopkins Epidemiology and Infection Control, the team is performing design, simulation, specification, testing, and – potentially – deployment of UV irradiation for small or large scale N95 decontamination.
- Testing Filter Integrity for Reprocessed N95 Masks. A second team of Surgineers (Zachary Baker and Paul Hage) are working with experts in Environmental Health and Engineering (Ana Rule and Kirsten Koehler) to develop a system to measure the integrity of reprocessed mask filters in terms of particle penetration (stoppage) and pressure drop (flow). The team are building the initial testing setup, developing a quality assurance model, and designing for potential deployment at-scale.
- Decontamination of CT Scanning Suites and Radiotherapy Treatment Rooms. CT scanning provides rapid assessment of respiratory disease in the Emergency Department and Critical Care Unit as well as diagnostic Radiology. Working in close collaboration with Radiology (Mahesh) and Radiation Oncology (Viswanathan, Quon, Kut, Wong, and McNutt), Siewerdsen and the surgineers are helping to develop systems to decontaminate the CT scanner suite using ultraviolet (UV) light, reducing the turnover time between patients and reducing the risk of infection to the tech / cleaning staff. The same principle applies to decontamination of radiation therapy treatment rooms. The teams are assembling systems for measurement and validation that rooms are decontaminated to an acceptable level and developing UV-C irradiation rigs for potential deployment in coordination with Radiology, Radiation Oncology, and Hopkins Epidemiology and Infection Control.
- Imaging of COVID-19. CT may be able to detect distinct patterns associated with COVID-19 – for example, more peripheral lung distribution and unique granular patterns. Similarly, chest radiography (CXR) allows rapid deployment of imaging and fast workflow with reduced infection risk in challenging environments, such as intensive care, field testing, and low-resource settings. I-STAR researchers are working with experts in Radiology (Tony Lin, Paul Yi, and Mahadevappa Mahesh) and BME (Jeremias Sulam) in what will hopefully involve a Hopkins-wide initiative for high performance imaging of COVID-19. The work includes: assurance of consistent CT and CXR imaging protocols across the Hopkins enterprise; collection and curation of data for COVID+/- patients; use of ultra-high-resolution CT that could reveal fine morphological patterns unique to COVID-19; radiologist analysis of image features specific to COVID-19; and image analytics to efficiently and accurately detect and/or monitor COVID-19 in CT and CXR images.
Such efforts are the tip of the iceberg in the extraordinary response at Johns Hopkins University to the COVID-19 emergency, including diagnostics, therapeutics, community research, protection of healthcare workers, innovations in medical supply, viral genetics, and data-intensive modeling. These efforts and more are summarized and updated regularly on the Hopkins HUB — and the COVID-19 Hopkins Research Response.
Travel Award and Presentation at the American Physical Society – Congratulations, Pengwei Wu!
Pengwei Wu – a PhD student in Biomedical Engineering at Johns Hopkins University – was awarded a Travel Award to attend the March Meeting of the American Physical Society (APS), held March 2-6 in Denver CO.
The award was granted by the GMED topical group on Medical Physics. The objective GMED is the advancement and diffusion of knowledge of physics in various areas of medicine.
Pengwei first-authored two abstract submissions:
Session A06: Physics of Medical Devices, chaired by Dr. Stephen Russek, NIST
Imaging Surgical Devices with Reduced Metal Artifact
Authors: Pengwei Wu, Niral Sheth, Alejandro Sisniega, Ali Uneri, Runze Han, Rohan Vijayan, Prasad Vagdargi, Bjoern Kreher, Holger Kunze, Gerhard Kleinszig, Sebastian Vogt, and Jeffrey H Siewerdsen
Metal artifacts from surgical devices present a major challenge to imagine quality in the OR. Imaging in the OR is essential for high-precision and minimally invasive spine surgery. Artifacts can cause spectral shift (beam-hardening), photon starvation, and scatter, which confound visualization in regions near surgical devices – e.g. to assess the accuracy of screw placement.
A method to predict patient and device specific orbits of C-arm cone-beam CT system that avoid metal artifacts by acquiring projection data with minimal influence from metal-related polyenergetic bias (spectral shift).The method localizes devices via neural network segmentation in a few low-dose scout views (commonly acquired for patient positioning), and all C-arm rotation and tilt angles are analyzed to identify the orbit with minimal polyenergetic bias.
The method was evaluated in simulation, phantoms, and a cadaver with multiple pedicle screws, demonstrating accurate prediction of orbits that optimally avoided metal artifacts. The results yielded ~200-500 HU reduction of shading artifacts, and ~30-45% reduction in blooming artifacts about the screw shaft. Such method can improve the safety and precision of spine surgery.
Session J13: Physics of Medical Imaging, Measurement, and Tissue Characterization, chaired by Dr. Wojciech Zbijewski (JHU)
Method, Mechanism, and Metrology for Measurement of Multi-Dimensional MTF in Medical Imaging
Authors: Pengwei Wu, Mahadevappa Mahesh, John Boone, and Jeffrey H Siewerdsen
The spatial resolution characteristics of CT and cone-beam CT (CBCT) systems is well characterized by the spatial-frequency-dependent modulation transfer function (MTF). Emerging scanner technologies and reconstruction algorithms challenge conventional methods for MTF assessment, including the degree to which the system / image exhibits 3D resolution characteristics that are isotropic (vary in direction), stationary (vary with location), and linear (vary with contrast). We report an angled-edge test tool and oversampling method to measure the MTF in any direction in 3D image data, with extension to a spherical test tool for measurement in all directions. One particular direction (45° relative to the axial plane) is shown to avoid null space effects in cone-beam geometries and provide useful 1D quantitation of the fully 3D resolution characteristics. This method was tested using a mobile C-arm CBCT system and a high-resolution diagnostic CT scanner and shown to reveal underlying sources of non-isotropic resolution characteristics – for example, asymmetric apodization filters, detector binning modes, and focal spot size. The angled-edge or spherical test tools provide a practical means for quantitative characterization of 3D MTF characteristics for medical imaging systems.
I-STARs Align at SPIE Medical Imaging 2020

With topics ranging from spectral CT to image-guided surgery and deep learning image analysis, the I-STARs come into alignment at the SPIE Medical Imaging conference in Houston TX. Papers include two nominees for the Robert F. Wagner all-conference best student paper award and one finalist for best student paper in the Physics of Medical Imaging conference. Presentations include:
SUNDAY 16-Feb-2020
An investigation of slot-scanning for mammography and breast CT
Andrew Leong, Grace J. Gang, Alejandro Sisniega, Wenying Wang, Jesse Wu, Shabbir B. Bambot, and Joseph W. Stayman
Sunday 16 February 2020 8:40 AM – 9:00 AM, Physics of Medical Imaging
Slot-scan dual-energy measurement of bone mineral density on a robotic x-ray system
Chumin Zhao,Christoph Luckner, Magdalena Herbst, Sebastian Vogt, Ludwig Ritschl, Steffen Kappler, Jeffrey H. Siewerdsen, and Wojciech Zbijewski
Sunday 16 February 2020 9:20 AM – 9:40 AM, Physics of Medical Imaging
Image-based deformable motion compensation in cone-beam CT: translation to clinical studies in interventional body radiology
Sarah Capostagno, Alejandro Sisniega, Joseph W. Stayman,Tina Ehtiati, Clifford R. Weiss, and Jeffrey H. Siewerdsen
Sunday 16 February 2020 11:30 AM – 11:50 AM, Image-Guided Procedures
*Finalist, Robert F. Wagner All-Conference Best Student Paper Award!
Multi-body registration for fracture reduction and guidance of orthopaedic trauma surgery
Runze Han, Ali Uneri, Pengwei Wu, Rohan C. Vijayan, Prasad Vagdargi, Michael D. Ketcha, Niral Sheth, Sebastian Vogt, Gerhard Kleinszig,Greg M. Osgood, and Jeffrey H. Siewerdsen
Sunday 16 February 2020 2:00 PM – 2:20 PM, Image-Guided Procedures
Calibration and registration of a freehand video-guided surgical drill for orthopaedic trauma
Prasad Vagdargi, Ali Uneri, Niral Sheth, Alejandro Sisniega, Tharindu De Silva, Greg M. Osgood, Jeffrey H. Siewerdsen
Sunday 16 February 2020 2:20 PM – 2:40 PM, Image-Guided Procedures
MONDAY 17-Feb-2020
Combining spectral CT acquisition methods for high-sensitivity material decomposition
Matthew Tivnan, Wenying Wang, Grace J. Gang, Eleni Liapi, Peter B. Noël, and Joseph W. Stayman
Monday 17 February 2020 9:20 AM – 9:40 AM, Physics of Medical Imaging
Pixelated columnar CsI:Tl scintillator for high resolution radiography and cone-beam CT
Stuart R. Miller, Bipin Singh, Matthew S. J. Marshall, Conner Brown, Niral Sheth, Jeffrey H. Siewerdsen, Wojciech Zbijewski, Vivek V. Nagarkar
17 February 2020 • 3:00 – 3:20 PM, Physics of Medical Imaging
Monday Night Poster Session
Model-based material decomposition with system blur modeling
Wenying Wang, Matthew Tivnan, Grace J. Gang, Yiqun Ma, Qian Cao, Minghui Lu, Josh Star-Lack, Richard E. Colbeth, Wojciech Zbijewski, and Joseph W. Stayman
Monday 17 February 2020 5:30 PM – 7:00 PM, Physics of Medical Imaging
Monday Night Poster Session
Data-driven detection and registration of spine surgery instrumentation in intraoperative images
Sophia A. Doerr, Ali Uneri, Yixuan Huang, Xiaoxuan Zhang, Patrick Helm, Nick Theodore, and Jeffrey H. Siewerdsen
Monday 17 February 2020 5:30 PM – 7:00 PM, Image-Guided Procedures
Monday Night Poster Session
Multi-slot extended view imaging on the O-Arm: image quality and application to intraoperative assessment of spinal morphology
Xiaoxuan Zhang, Ali Uneri, Michael D. Ketcha, Sophia A. Doerr, Patrick A. Helm, and Jeffrey H. Siewerdsen
Monday 17 February 2020 5:30 PM – 7:00 PM, Image-Guided Procedures
Monday Night Poster Session
Multi-slot intraoperative imaging and 3D-2D registration for evaluation of long surgical constructs in spine surgery
Ali Uneri, Xiaoxuan Zhang, Michael D. Ketcha, Sophia A. Doerr, Patrick A. Helm, Jeffrey H. Siewerdsen
Monday 17 February 2020 5:30 PM – 7:00 PM, Image-Guided Procedures
TUESDAY 18-Feb-2020
Image-guided robotic K-Wire placement for orthopaedic trauma surgery
Rohan C. Vijayan, Runze Han, Pengwei Wu, Niral M. Sheth, Michael D. Ketcha, Prasad Vagdargi, Sebastian Vogt, Gerhard Kleinszig, Greg M. Osgood, Ali Uneri, and Jeffrey H. Siewerdsen
Tuesday 18 February 2020 1:40 PM – 2:00 PM, Image-Guided Procedures
Estimation of local deformable motion in image-based motion compensation for interventional cone-beam CT
Alejandro Sisniega, Sarah Capostagno, Wojciech Zbijewski, Joseph W. Stayman, Clifford R. Weiss, Tina Ehtiati, and Jeffrey H. Siewerdsen
Tuesday 18 February 2020 4:10 PM – 4:30 PM, Physics of Medical Imaging
WEDNESDAY 19-Feb-2020
Quantitative assessment of weight-bearing fracture biomechanics using extremity cone-beam CT
Stephen Z. Liu, Qian Cao, Greg M. Osgood, Jeffrey H. Siewerdsen, J. Webster Stayman, Wojciech Zbijewski
Wednesday 19 February 2020 • 8:00 – 8:20 AM, Biomedical Applications in Molecular, Structural, and Functional Imaging
SpineCloud: image analytics for predictive modeling of spine surgery outcomes
Tharindu S. De Silva, Sathyanarayana Vedula, Alexander Perdomo-Pantoja, Rohan C. Vijayan, Sophia A. Doerr, Ali Uneri, Runze Han, Michael D. Ketcha, Richard L. Skolasky, Timothy Witham, Nicholas Theodore, and Jeffrey H. Siewerdsen
Prospective prediction and control of image properties in model-based material decomposition for spectral CT
Wenying Wang, Matthew Tivnan, Grace J. Gang, and Joseph W. Stayman
Wednesday 19 February 2020 1:20 PM – 1:40 PM, Physics of Medical Imaging
*Finalist, Robert F. Wagner All-Conference Best Student Paper Award!
Method for metal artifact avoidance in C-Arm cone-beam CT
Pengwei Wu, Niral Sheth, Alejandro Sisniega, Ali Uneri, Runze Han, Rohan Vijayan, Prasad Vagdargi, Bjoern Kreher, Holger Kunze, Gerhard Kleinszig, Sebastian Vogt, and Jeffrey H. Siewerdsen
Wednesday 19 February 2020 4:10 PM – 4:30 PM, Physics of Medical Imaging
Non-circular CT orbit design for elimination of metal artifacts
Grace J. Gang, Joseph W. Stayman, and Jeffrey H. Siewerdsen
Wednesday 19 February 2020 4:30 PM – 4:50 PM, Physics of Medical Imaging
THURSDAY 20-Feb-2020
Application of a novel ultra-high resolution multi-detector CT in quantitative imaging of trabecular microstructure
Gengxin Shi, Shalini Subramanian, Qian Cao, Shadpour Demehri, Jeffrey H. Siewerdsen, Wojciech Zbijewski
20 February 2020 • 1:20 – 1:40 PM, Biomedical Applications in Molecular, Structural, and Functional Imaging
Surgineering: New Curriculum at the Cutting Edge

Following its first run in Fall semester 2018, the Surgineering course is underway again in 2019-2020, giving engineering students a new experience and priceless learning opportunity alongside clinicians at Johns Hopkins Hospital. The course was started by Jeff Siewerdsen (Hopkins Biomedical Engineering), who cites his own graduate experience as formative to his perspective on medical research and innovation. “I was lucky,” says Siewerdsen. “The labs where I did my PhD and my postdoc were in the heart of great hospitals. And now, as a teacher and researcher, I wouldn’t want to work anywhere else.”
The Surgineering course aims to give engineering students a similar experience and inspiration by learning hands-on fundamentals and challenges in surgery, interventional radiology, and radiation oncology. Class starts early in the morning at the Hopkins Med Campus, with students ready in green scrubs, and Hopkins doctors leading most every class. Following brief introduction, students dive in with anatomical models, interventional tools, and visits to clinical theaters – each helping to build an understanding of fundamentals, an appreciation for real clinical challenges, and an appreciation of the true-to-life context and the numerous stakeholders surrounding each patient.
PHOTOS (link) from the 2019 Fall semester illustrate the Surgineering classes.
A PAPER (link) in the Journal for Computer-Assisted Radiology and Surgery details the first run of the curriculum.
An ARTICLE in Hopkins Medicine magazine (link) describes the original concept and motivation.
“The course would not be possible without the time and expertise from clinical collaborators,” says Siewerdsen. “They provide the insight and inspiration that students find so valuable.”
Dr. Gina Adrales co-directs several classes in the MISTIC (Minimally Invasive Surgical Training and Innovation Center), focusing on laparoscopy and robot-assisted surgery with the DaVinci robot.
Dr. Mike Marohn leads classes that span both fundamentals – such as cautery, suturing, and principles of antiseptic surgery – and challenges to impactful innovation in the OR.
Dr. Stan Anderson leads classes in neurosurgery, including deep brain stimulation, image guidance, and robotic assistance.
Principles and hands-on in ENT surgery are covered by Dr. John Carey, Dr. Pete Creighton, Dr. Deepa Galaiya – including cochlear implants and stapedotomy – and skull base neurosurgical approaches are covered by Dr. Nick Rowan and Dr. Wataru ishida.
Dr. Greg Osgood leads classes in orthopaedic trauma and joint replacement surgery, including hands-on with anatomical models, tools, and intraoperative imaging.
In addition to surgical specialities, the course includes introduction to the spectrum of procedures performed in interventional radiology Dr. Cliff Weiss leads classes that include ultrasound-guided biopsy, tumor ablation (microwave, RF, and cryo-ablation), and visits to interventional suites with intraoperative x-ray imaging, CT, and MRI.
Rounding out the course is an introduction to radiation oncology, including 3D treatment planning led by Dr. Todd McNutt, image-guided radiotherapy led by Dr. John Wong, and image-guided brachytherapy led by Dr. Akila Viswanathan.
Following the Fall semester (BME 580.74 “Surgery for Engineers”), the course continues in Spring (BME 580.750 “Surgineering”) in classes that are even more immersive in real clinical problems with students rotating through internships in 3 or 4 clinical departments. From deep clinical observership, students learn challenges to daily clinical workflow, patient safety, systems engineering, and data science.
The course culminates with projects carried out by surgineering teams in the spring. Example projects in 2018 include:
- 3D / 4D workflow simulator for MR-guided neurosurgery. (surgineers, Sarah Capostagno and Nicole Chernavsky)
- Using anesthesia time-series data to predict patient status and OR progress. (surgineers, Prasad Vagdargi and Gabriel Anfinrud)
- Ease-of-use EPIC queries with a voice recognition tool. (surgineers, Brian Morris and Patrick Myers)
- A video-based OR progress monitor. (surgineers, Sophia Doerr and Runze Han)
The course continues to expand and deepen, with future clinical collaboration in Opthalmology, Anesthesiology, Physical Rehabilitation, and Emergency Medicine as well as increased interaction with the Johns Hopkins Capacity Command Center and the Armstrong Institute for Patient Safety and Quality.
Meet the Corgi! A Modular Phantom for Cone‐Beam CT Dose and Image Quality
 Jeff Siewerdsen (Hopkins BME) and John Boone (UC Davis) teamed up to produce a new imaging phantom that combines dose measurement and imaging performance evaluation in a compact, modular form suitable to a broad range of cone-beam CT (CBCT) systems. The concepts underlying the phantom were published in the Medical Physics journal (link):
Jeff Siewerdsen (Hopkins BME) and John Boone (UC Davis) teamed up to produce a new imaging phantom that combines dose measurement and imaging performance evaluation in a compact, modular form suitable to a broad range of cone-beam CT (CBCT) systems. The concepts underlying the phantom were published in the Medical Physics journal (link):
JH Siewerdsen, A Uneri, AM Hernandez, GW Burkett, and JM Boone, “Cone‐beam CT dose and imaging performance evaluation with a modular, multipurpose phantom,” Med Phys (2019) https://doi.org/10.1002/mp.13952
The phantom (dubbed the “Corgi”) includes a modular arrangement for measurement of image uniformity, HU linearity and accuracy, contrast, CNR, spatial resolution (modulation transfer function, MTF), noise, and noise-power spectrum (NPS). Software was developed to automatically compute all of these performance metrics automatically and summarize a full technical assessment within a standardized, structured report.
Initial testing of the phantom included a survey of CBCT systems for orthopaedics imaging, breast imaging, image-guided surgery, angiography, and image-guided radiation therapy. The phantom is also applicable to CBCT systems for dental and ENT imaging.
The collaboration between Hopkins and UC Davis builds from ongoing research spanning nearly two decades, with Siewerdsen’s work focusing on CBCT for image-guided procedures and Boone’s on 3D breast imaging.
“The phantom addresses a growing need in the medical physics community,” says Boone. “There is no single tool that is well suited to such a full range of quantitative tests, includes functionality for dose measurement, and combines all of that with automated software to enable routine, reproducible characterization of quantitative performance.”
Mobile CT for Image-Guided Brachytherapy: Paper by Nicole Chernavsky Assesses Image Quality and Dose
 A paper by Nicole E. Chernavsky (MSE graduate in Biomedical Engineering at Johns Hopkins University) reports the imaging performance and radiation dose associated with a mobile CT scanner (Brainlab Airo®) for image-guided procedures.
A paper by Nicole E. Chernavsky (MSE graduate in Biomedical Engineering at Johns Hopkins University) reports the imaging performance and radiation dose associated with a mobile CT scanner (Brainlab Airo®) for image-guided procedures.
The mobile CT system has been used widely in recent years for image-guided spine surgery, and Nicole’s work investigates its use in image-guided brachytherapy – specifically, in guiding treatment of gynecologic cancers. The scanner offers a number of promising logistical characteristics, including a small footprint, ease in patient transfer, and a large bore compatible with the patient setup. However, its imaging characteristics with respect to anatomical structures and implanted devices in brachytherapy have not previously been investigated.
Nicole’s paper includes measurements of spatial resolution (modulation transfer function, MTF) and image noise-power spectrum (NPS, which affects soft-tissue contrast resolution) for a range of imaging contexts pertinent to guiding interventional procedures in the body. Images were also obtained on a diagnostic CT scanner (Big Bore CT, Philips Healthcare) as a basis of comparison. Performance in application to brachytherapy was assessed using a set of anthropomorphic phantoms including realistic brachytherapy implants / applicators.
The results demonstrated a high degree of HU accuracy and CT number linearity for both axial and helical scan modes. Contrast-to-noise ratio was suitable for soft-tissue visualization, but a variety of artifacts (including windmill sampling artifacts in helical mode) posed challenges to image quality. The metal artifact reduction (MAR) algorithm provided a modest improvement in the presence of metal implants, and overall image quality appeared suitable to relevant clinical tasks in intracavitary and interstitial (e.g., gynecological) brachytherapy, including visualization of soft‐tissue structures in proximity to the applicators.
The paper was published in the Journal of Applied Clinical Medical Physics
Nicole E. Chernavsky, Marc Morcos, Pengwei Wu, Akila N. Viswanathan, and Jeffrey H. Siewerdsen, Technical assessment of a mobile CT scanner for image‐ guided brachytherapy J. Appl. Clin. Med. Phys. 2019 DOI: 10.1002/acm2.12738
Michael Ketcha Named a 2020 Siebel Scholar
 Michael Ketcha was named among the distinguished 2020 class of Siebel Scholars. The competitive award is offered to just five PhD students each year in recognition of groundbreaking research, high academic standing,excellence in leadership.
Michael Ketcha was named among the distinguished 2020 class of Siebel Scholars. The competitive award is offered to just five PhD students each year in recognition of groundbreaking research, high academic standing,excellence in leadership.
Since joining the I-STAR Lab, Michael’s research has focused on the mathematics of medical image quality and image registration performance. He derived fundamental relationships relating image quality characteristics (for example, spatial resolution and image noise) to image registration performance. His model correctly predicts registration performance for registration of CT and cone-beam CT images for image-guided surgery and offers a practical platform by which both imaging protocols and registration algorithms can be optimized.
Michael’s work also yielded a method for deformably registering anatomical labels from preoperative 3D images to intraoperative x-ray radiographs – a “multi-scale deformable 3D2D registration” approach. His method was shown to be accurate in registering information from preoperative CT in spine surgery even under conditions of strong anatomical deformation – e.g., changes in patient position and spinal curvature during surgery.
More recently, Michael tackled an important question in the development of convolutional neural networks (CNNs) for deformable image registration. Specifically, he investigated how the performance of a CNN registration varies when the image quality of the target image differs significantly from that of the training data. His results showed that while performance is optimal when image quality is matched, a training set that is diverse in its image quality characteristics can obtain near equivalent performance. His work provides practical guidance to the development of CNN methods for registering images that vary widely in their image quality – for example, CT images from large disparate datasets in which scan protocols vary considerably.
Michael completed an EDGE internship with Medtronic in the summer of 2019, where he worked on 3D imaging for image-guided spine surgery. He also worked with the EDGE Program as Co-Director of internships and helped to organize a PhD Career Fair featuring 20 companies. He previously served as Co-Director for the Hopkins Imaging Conference, mentored in the Thread Program for Baltimore high schools, and was Vice President of Academic Affairs in the BME PhD Council.
A truly stellar I-STAR… Congratulations, Michael!
Metal Artifact Reduction for Surgical Implants in Cone-Beam CT
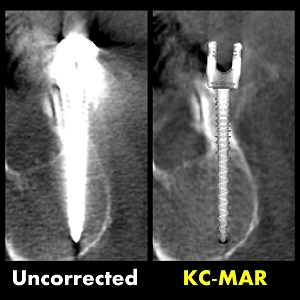 Metal artifacts arise from at least three main factors in CT or cone-beam CT: (1) spectral shifts (beam hardening) in the transmitted x-ray beam that are inconsistent from one projection to the next; (2) strong attenuation by metal implants (photon starvation), resulting in low detector signal, poor SNR, and strongly correlated noise in 3D image reconstruction; and (3) high-spatial-frequency, high-contrast edges of metal implants to which high-pass filtering and backprojction / reconstruction can be sensitive with respect to partial volume effects and small errors in system geometry. Together, these effects can cause strong streak and shading artifacts that confound visualization – often in the very region of interest (for example, assessing the placement of a surgical device relative to adjacent bone and soft-tissue anatomy).
Metal artifacts arise from at least three main factors in CT or cone-beam CT: (1) spectral shifts (beam hardening) in the transmitted x-ray beam that are inconsistent from one projection to the next; (2) strong attenuation by metal implants (photon starvation), resulting in low detector signal, poor SNR, and strongly correlated noise in 3D image reconstruction; and (3) high-spatial-frequency, high-contrast edges of metal implants to which high-pass filtering and backprojction / reconstruction can be sensitive with respect to partial volume effects and small errors in system geometry. Together, these effects can cause strong streak and shading artifacts that confound visualization – often in the very region of interest (for example, assessing the placement of a surgical device relative to adjacent bone and soft-tissue anatomy).
Metal artifact reduction (MAR) algorithms abound in CT and cone-beam CT. However, many methods are limited by imprecise localization / segmentation of metal objects from which shading and streak artifacts arise. For example, some MAR methods proceed by: (i) forming an uncorrected 3D image reconstruction; (ii) segmenting metal objects in the uncorrected 3D image; (iii) forward-projecting the segmentation; (iv) applying detector pixel corrections within the forward-projected regions; and (v) reconstructing the corrected projection data to yield the MAR image. However, the segmentation step (ii) can be notoriously difficult, and even with iteration over the entire (i)-(v) algorithm, small segmentation errors can result in significant residual streak artifacts.
A new algorithm reported by Ali Uneri and coauthors uses knowledge of the implant shape to obtain highly accurate localization / segmentation of the implant by 3D-2D “known-component” registration (KC-Reg). Referred to as Known-Component Metal Artifact Reduction (KC-MAR), the method was shown to minimize segmentation errors and yield cone-beam CT image reconstructions with strong reduction in metal artifact.
The paper includes phantom studies and realistic cadaver studies emulating image-guided spine surgery, where clear visualization of pedicle screws is important to assessing the accuracy of device placement and the quality of the surgical product. The phantom studies showed how even small segmentation errors (as small as ~1 pixel) can result in strong residual metal artifacts and helped to guide parameter selection for the KC-MAR algorithm. The cadaver studies showed near elimination of metal artifacts in cone-beam CT images acquired under clinically realistic conditions – with streak artifacts reduced from hundreds of HU in magnitude to as little as 5-10 HU.
The KC-MAR algorithm and experiments were published in Physics in Medicine & Biology, Volume 64, Number 16.
The paper is available for download here:
https://iopscience.iop.org/article/10.1088/1361-6560/ab3036/meta
Dr. Ali Uneri Joins Hopkins BME as Research Faculty
 We are thrilled to welcome Dr. Ali Uneri to the BME faculty in the Johns Hopkins School of Medicine. As a Research Associate faculty member, Dr. Uneri works in areas of image-guided surgery, machine learning approaches for 3D image registration and reconstruction, and development of novel surgical robotics systems.
We are thrilled to welcome Dr. Ali Uneri to the BME faculty in the Johns Hopkins School of Medicine. As a Research Associate faculty member, Dr. Uneri works in areas of image-guided surgery, machine learning approaches for 3D image registration and reconstruction, and development of novel surgical robotics systems.
Dr. Uneri earned his PhD in Computer Science at Johns Hopkins University working with Professor Jeff Siewerdsen in the I-STAR Lab and Professor Russ Taylor at the LCSR. His dissertation included work on novel image registration methods (including the Known-Component Registration “KC-Reg” method for 3D2D registration). He is also the architect of the TREK software platform for systems integration in surgical guidance and mentored undergraduate research assistants in the development of an image-guided robot for spine surgery.
In his postdoctoral work, Dr. Uneri worked to improve intraoperative 3D image quality on the Medtronic O-Arm, including development of model-based 3D image reconstruction (MBIR) for low-dose imaging and methods for metal artifact reduction (the Known-Component “KC-MAR” method for metal artifact reduction). He also mentored a PhD student in the development of an image-guided robot for trauma surgery – an area of ongoing interest.
Dr. Uneri has had tremendous impact in the I-STAR Lab, including many aspects of the computing architecture for 3D imaging and registration. As faculty in BME, he is building a strong program in image-guided surgical robotics and continues to be a tremendous collaborator on multiple projects.
Congratulations, Dr. Uneri — and welcome to the faculty in Hopkins BME!
This year marks the 10th Anniversary of the I-STAR Lab at Hopkins BME.
 The team celebrated at the Baltimore Inner Harbor with food and good cheer aboard The Raven. Several alumni made the trip to Baltimore to celebrate, including:
The team celebrated at the Baltimore Inner Harbor with food and good cheer aboard The Raven. Several alumni made the trip to Baltimore to celebrate, including:Josh Punnoose (former undergraduate research assistant, now a PhD student at U Minnesota)
Paper by Rohan Vijayan Yields a Method for Automatic Planning in Spine Surgery
Numerous ongoing advances aim to improve the accuracy, safety, and efficacy of sp ine surgery, which often involves the placement of pedicle screws to stabilize the spine in treatment of deformity, degeneration, or trauma. Examples include the use of 3D surgical navigation and robot-assisted surgery as well as intraoperative imaging for operating room quality assurance (ORQA) and evaluation of the surgical product. An additional area of growing interest involves image analytics for data-intensive predictive modeling as a means of clinical decision support, patient selection, and optimal planning.
ine surgery, which often involves the placement of pedicle screws to stabilize the spine in treatment of deformity, degeneration, or trauma. Examples include the use of 3D surgical navigation and robot-assisted surgery as well as intraoperative imaging for operating room quality assurance (ORQA) and evaluation of the surgical product. An additional area of growing interest involves image analytics for data-intensive predictive modeling as a means of clinical decision support, patient selection, and optimal planning.
All of these advances require some form of reference plan – a reliable definition of how pedicle screws should be oriented in the spine, and what types of screws are best suited to patient-specific anatomy. In surgical navigation and robot-assisted surgery, such planning is the “roadmap” by which screws are to be placed. In ORQA and surgical data science, such planning gives a reference from which to analyze deviations in device placement that might affect the quality of the surgical product. Conventionally, planning is performed manually by the surgeon – introducing a time bottleneck that does not support broad utilization of these advanced technologies and is not scalable to data-intensive (“big data”) approaches.
A recent paper by Rohan Vijayan (PhD student in Biomedical Engineering at Johns Hopkins University) and coauthors in the I-STAR Lab reports a new algorithm to automatically compute spine surgery plans to obtain accurate, reproducible, definitions of pedicle screw trajectories and screw size. The method operates with a minimum of user interaction and does not require segmentation of the patient CT images. Instead, the algorithm uses a statistical atlas that describes not only the shape variations of vertebrae but also contains ideal reference screw trajectories within each member of the atlas. By computing a deformable 3D atlas-to-CT registration, the ideal trajectories can be precisely morphed to the patient CT. The atlas can even be customized to reflect individual preferences of a particular surgeon.
The algorithm was tested in IRB studies involving offline analysis of 40 cases, demonstrating accurate trajectory definition within 2.4 mm and 3.6 degrees. The algorithm also computes the maximum diameter of screw that can safely traverse the spinal pedicle, and the maximum length that will provide strong purchase in the vertebral body without breach. The algorithm was also shown to be accurate in intraoperative cone-beam CT (CBCT) such as that acquired with a mobile C-arm or O-arm and to be robust even with very low-dose imaging protocols.
The paper was published in Physics in Medicine and Biology, 2019
Vijayan RC, De Silva T, Han R, Zhang X, Uneri A, Doerr SA, Ketcha MD, Perdomo-Pantoja A, Theodore N, Siewerdsen JH, “Automatic Pedicle Screw Planning Using Atlas-Based Registration of Anatomy and Reference Trajectories.” Physics in Medicine and Biology, 2019, doi:10.1088/1361-6560/ab2d66
I-STARs at the AAPM Meeting in San Antonio, TX
 A dozen talks from the I-STAR Lab and AIAI Lab at the 2019 Meeting of the American Association of Physicists in Medicine (AAPM) in San Antonio, Texas! Topics and talks include:
A dozen talks from the I-STAR Lab and AIAI Lab at the 2019 Meeting of the American Association of Physicists in Medicine (AAPM) in San Antonio, Texas! Topics and talks include:
ANALYSIS OF 3D IMAGE QUALITY
Grace J. Gang et al. – Generalized Image Quality Analysis for Nonlinear Algorithms in CT
Qian Cao et al. – Cone-beam CT of load-bearing surgical hardware using a mechanical model of implant deformation
Wenying Wang et al. – Generalized local impulse response prediction in model-based material decomposition of spectral CT
Ali Uneri et al. – The Corgi: a multi-purpose modular phantom for dose and image quality assessment in cone-beam CT
3D IMAGE RECONSTRUCTION
Alejandro Sisniega et al. – Accelerated model-based iterative reconstruction using a multi-level morphological pyramid
Matthew Tivnan et al. – Designing Spatial-Spectral Filters for Spectral CT
Jessica Flores et al. – Reconstruction of difference with anatomical change preserving deformable registration for sequential lung cancer screening
IMAGE-GUIDED SURGERY
Esme (Xiaoxuan) Zhang et al. – Known-Component Metal Artifact Reduction for Intraoperative Cone-Beam CT in Spine Surgery: A Clinical Pilot Study
Niral Sheth et al. – Technical Assessment of Dose and 3D Imaging Performance for a New Mobile Isocentric C-Arm for Intraoperative Cone-Beam CT
Runze Han et al. – Pelvic Dislocation Reduction Guidance for Orthopaedic Trauma Surgery Using Atlas-based Registration and Known Component 3D-2D Registration
Jeff Siewerdsen, Kevin Cleary, Michael Miga, and Joseph Paydarfar – Advances in Image-Guided Interventions
Esme Zhang Reports Clinical Study of 3D Imaging with Known-Component Reconstruction
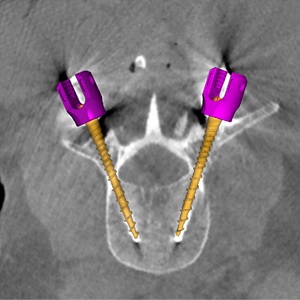 Intraoperative 3D imaging plays an important role in guidance of minimally invasive surgery. The ability to see the surgical target, nearby normal tissues, and surgical instrumentation inside the body with little more than a keyhole incision allows surgeons to operate with increased precision and reduced collateral damage and can reduce the length of postoperative recovery in the hospital. Intraoperative CT and cone-beam CT are important means of accomplishing these goals, but image quality is often confounded by image noise and artifacts surrounding metal instrumentation, challenging visualization in the very regions where the surgeon needs to see.
Intraoperative 3D imaging plays an important role in guidance of minimally invasive surgery. The ability to see the surgical target, nearby normal tissues, and surgical instrumentation inside the body with little more than a keyhole incision allows surgeons to operate with increased precision and reduced collateral damage and can reduce the length of postoperative recovery in the hospital. Intraoperative CT and cone-beam CT are important means of accomplishing these goals, but image quality is often confounded by image noise and artifacts surrounding metal instrumentation, challenging visualization in the very regions where the surgeon needs to see.
A recent paper by Xiaoxuan (Esme) Zhang and coauthors in the I-STAR Lab at Hopkins BME reports on a promising solution to improving 3D image quality in the presence of metal instruments. The method involves 3D model‐based image reconstruction (MBIR) method called “Known‐Component Reconstruction” (KC‐Recon), an algorithm that was first reported by Stayman et al. in a paper in 2012. The KC-Recon algorithm reduces image noise (improves visibility of soft tissues) by way of penalized weighted least squares (PWLS) optimization and reduces artifacts associated with metal implants by way of a joint registration-reconstruction method that incorporates knowledge of instrumentation within the image – for example, the shape and composition of surgical instruments.
The recent paper by Esme represents the first translation of the KC-Recon method to clinical studies – a pilot study involving 17 spine surgery cases. Images acquired during surgery were transferred offline under an IRB protocol, and KC-Recon images were analyzed in comparison to conventional 3D image reconstruction methods. KC-Recon yielded ~24% increase in soft‐tissue contrast resolution and markedly improved visualization of paraspinal muscles, major vessels, and other soft‐tissues about the spine. A total of 72 spine screws of various makes and models were analyzed in the study, and KC‐Recon yielded a significant reduction (~65%, p<<0.01) in metal artifacts around the screw shaft and tip. Clearer visualization of screws within the vertebrae allows more confident verification and quality assurance that the surgical construct is delivered safely within the pedicle without breach of the spinal dura or adjacent nerves or vessels.
The study was conducted in close collaboration between Hopkins BME and the Neurosurgical Spine Center in the Department of Neurosurgery at Johns Hopkins Hospital, including Dr. Nicholas Theodore, PI of the clinical study, and Dr. Larry Lo. “Improving 3D image quality in the OR is vital to advancing the state of the art in spine surgery,” says Dr. Theodore, “including robot-assisted surgery and improving the quality of surgical outcomes.”
Senior author Dr. Jeff Siewerdsen supervised the research as part of his project on Imaging for OR Quality Assurance (ORQA). “Over the last decade, we have worked on numerous advanced methods for 3D image reconstruction to improve image quality and reduce dose,” says Dr. Siewerdsen. “Esme’s work is especially interesting, because it not only represents the cutting edge of such advanced algorithms but it translates the method to real application in clinical studies and shows quantifiable benefit.”
First author Esme Zhang was a research scientist at Hopkins BME and the Carnegie Center for Surgical Innovation during this work, and she joins the PhD Program in BME in Fall 2019, where her research will involve new methods for 3D imaging and registration in image-guided surgery. “This project had it all,” says Esme. “Besides getting to work on complex algorithms and make them even better, I got to work right in the ORs at Hopkins Hospital. I had to be ready at a moment’s notice on nights and weekends – whatever the surgeons needed for this study – and I got to see how image-guided surgery is really done.”
Industry collaborators included Dr. Patrick Helm (Medtronic) and Dr. Neil Crawford (Globus Medical) who provided specification on spine screw models. Mr. Josh Hasson and Mr. William Mason (Medtronic) helped with the 3D imaging system (O2 O-arm, Medtronic) used in this work.
The paper was published in Medical Physics.
Xiaoxuan Zhang, Ali Uneri. J. Webster Stayman, Corinna C. Zygourakis, Sheng‐fu L. Lo, Nicholas Theodore, and Jeffrey H. Siewerdsen, “Known‐component 3D image reconstruction for improved intraoperative imaging in spine surgery: A clinical pilot study,” Med. Phys. (2019) https://doi.org/10.1002/mp.13652
Journal Article by Alex Sisniega Brings CT Motion Artifacts into Focus
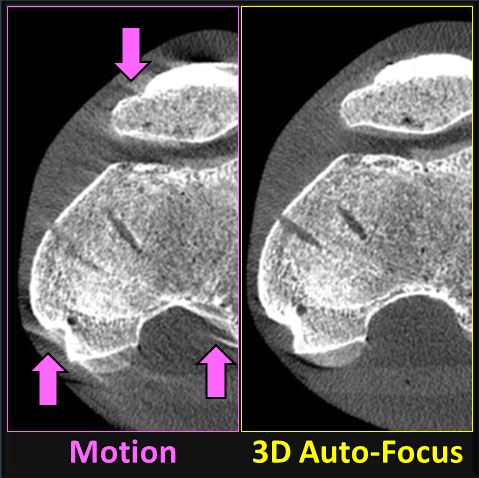
High resolution computed tomography (CT) and cone-beam CT (CBCT) requires not only a high-resolution detector, fine x-ray focal spot, reliable system calibration, and sharp 3D image reconstruction methods, it also requires that the patient remain stationary during the scan. A challenge to CBCT systems dedicated for high-resolution imaging of the extremities (foot, knee, etc.) is the potential for patient motion during the relatively long (10-20 sec) scans. Even a millimeter of patient motion can degrade image quality and confound the high-resolution imaging capability of the system.
A recent paper by Dr. Alejandro Sisniega (faculty Research Associate in Biomedical Engineering) and collaborators in the I-STAR Lab, the Department of Radiology, and Department of Orthopaedic Surgery at Johns Hopkins University reports a 3D image “auto-focus” method that compensates for patient motion in CBCT. The 3D autofocus involves an optimization that solves for complex, non-periodic motion of the subject to maximize image sharpness. Their study included an IRB-approved clinical protocol in which 24 scans acquired of 22 patients were imaged with CBCT for diagnostic evaluation of knee pathology, including osteoarthritis, osteoporosis, and trauma. Images were reconstructed with and without the 3D image autofocus technique, and an expert reader study was conducted to evaluate image quality improvements, particularly in relation to high-resolution imaging tasks – e.g., evaluation of bone trabeculae or fine fractures.
The results demonstrated measurable improvement in diagnostic quality. The fraction of cases for which the task performance was assessed by expert radiologists as “Fair” or better increased from less than 10% without motion compensation to 40–70% using the 3D image autofocus motion compensation method. The study concludes that using motion compensation significantly improved the visualization of bone and soft tissue structures in extremity CBCT for cases exhibiting patient motion.
The paper was published in the Journal of the International Skeletal Society A Journal of Radiology, Pathology and Orthopedics.
Alejandro Sisniega, Gaurav K. Thawait, Delaram Shakoor, Shadpour Demehri, Wojciech Zbijewski, and Jeffrey H. Siewerdsen, Motion compensation in extremity cone-beam computed tomography.et al. Skeletal Radiol (2019) https://doi.org/10.1007/s00256-019-03241-w
Paging the Surgineer! New Course Combines Data Science, Systems Engineering, and Clinical Immersion at Hopkins Hospital
 A new course at Hopkins BME combines principles of data science, systems engineering, and human factors with clinical immersion in interventional medicine at Hopkins Hospital. In the first run of the course – Surgineering, students from BME and Computer Science underwent clinical immersion in Neurosurgery, Orthopaedic Surgery, General Surgery, Otolaryngology, Interventional Radiology, and Radiation Oncology to identify systems-level challenges in workflow, patient safety, and data capture. Their aim: bury complexity in the operating theatre and develop systems for continuous data capture, curation, and learning.
A new course at Hopkins BME combines principles of data science, systems engineering, and human factors with clinical immersion in interventional medicine at Hopkins Hospital. In the first run of the course – Surgineering, students from BME and Computer Science underwent clinical immersion in Neurosurgery, Orthopaedic Surgery, General Surgery, Otolaryngology, Interventional Radiology, and Radiation Oncology to identify systems-level challenges in workflow, patient safety, and data capture. Their aim: bury complexity in the operating theatre and develop systems for continuous data capture, curation, and learning.
The course concluded with final projects, including:
– Workflow Simulation in MR-Guided Neurosurgery. Surgineers Sarah Capostagno and Nicole Chernavsky used FlexSimHealth to model the IMRIS operating theatre and identify improvements to workflow, efficiency, and safety.
– An NLP Assistant for EPIC Integration. Surgineers Brian Morris and Patrick Myers used Alexa voice recognition to perform efficient queries on data retrieval in EPIC.
– State Prediction Using Anesthesia Data Monitoring. Surgineers Prasad Vagdargi and Gabriel Anfinrud developed a machine learning classification method to classify OR status according to signals read from the anesthesia gas cart.
– Surgical Instruments Recognition. Surgineers Runze Han and Sophia Doerr developed a neural network image classification method to automatically recognize tools on the OR back table, creating a platform for numerous applications to enhance workflow and improve OR setup.
Clinical mentors at Johns Hopkins Hospital provided deep clinical insight on real-life clinical problems: Dr. Mike Marohn and Dr. Gina Adrales in General Surgery; Dr. Greg Osgood in Orthopaedic Surgery; Dr. Nick Theodore in Neurosurgery; Dr. Cliff Weiss in Interventional Radiology; Dr. Akila Viswanathan in Radiation Oncology; and Dr. John Carey and Dr. Fancis Creighton in Otolaryngology.
Congratulations, Surgineers! on an outstanding semester.
Double-Feature! A Pair of Papers by Sarah Capostagno, Web Stayman, and the I-STAR Team Show Task-Driven Orbits for Cone-Beam CT on a Robotic C-Arm
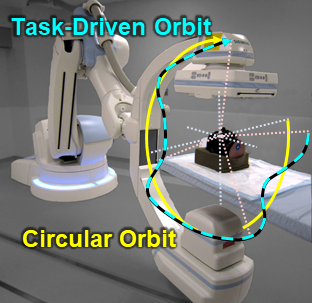
Robotic C-arms like the Artis Zeego (Siemens Healthineers) open new possibilities for cone-beam CT (CBCT) scanning beyond conventional circular orbits of the x-ray source and detector. Such motion capabilities permit scan orbits that expand the CBCT field of view, improve image quality, and reduce artifacts. A recent set of papers (1 and 2) co-authored by Sarah Capostagno (PhD student in Biomedical Engineering at Johns Hopkins University) and J. Webster Stayman (Associate Professor in Biomedical Engineering at Johns Hopkins University) leverages the capabilities of such robotic C-arm gantries to improve image quality using non-circular orbits computed to maximize imaging performance with respect to a particular imaging task.
Part I presents a mathematical framework to compute source-detector trajectories in CBCT that are optimal to a particular imaging task. Given a model of the patient (for example, a prior CT) and a specification of the structure of interest (namely, its location and spatial-frequency content), the framework solves for the scan orbit that maximizes performance of the task. The paper (1) gives a comprehensive introduction to the analytical framework, discusses various objective functions and practical optimization methods, and presents simulations in phantoms that provide intuition on the optimization process and demonstrate the potential for improved image quality.
Part II develops and applies the methodology from Part I to specific clinical scenarios in neurointerventional radiology, including embolization of neurovascular aneurysms and ablation of arteriovenous malformations (AVMs). The paper (2) tests the task-driven orbits concept on a laboratory test-bench for CBCT and translates the methodology for the first time to a clinical robotic C-arm (Artis Zeego) at Johns Hopkins Hospital.
The papers were published in the Journal of Medical Imaging, 2019.
Congratulations to Dr. Tharindu De Silva!
Dr. Tharindu De Silva worked with The I-STAR Lab on topics of image registration and surgical guidance. As a postdoctoral fellow in Biomedical Engineering at Johns Hopkins University, he helped to develop the LevelCheck algorithm for spine surgery and to build the SpineCloud platform for data-intensive image analytics. Following his great work at the I-STAR Lab, Tharindu is now joining the National Institutes of Health as a research scientist working on topics of image analysis.
Tharindu joined the I-STAR team in July 2014 and worked on a wide range of topics, including 3D2D registration (CT, MRI, and fluoroscopy), multi-modality image segmentation, ultrasound guidance, and surgical data science. His PhD research at the University of Western Ontario included automatic segmentation and registration for robot-assisted brachytherapy. A summary of Tharindu’s work can be found on Google Scholar.
Automatic Planning and Guidance for Trauma Surgery – New Paper by Runze Han et al.
Percutaneous screw fixation in pelvic trauma surgery is a challenging pr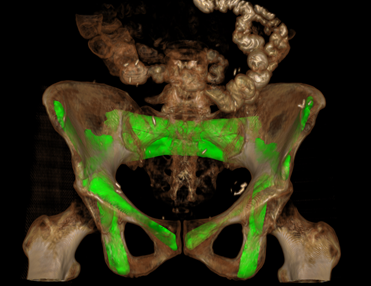 ocedure that often requires long fluoroscopic exposure times and trial-and-error insertion attempts along narrow bone corridors of the pelvis. A recent paper by Runze Han (PhD student in Biomedical Engineering at Johns Hopkins University) and colleagues at the I-STAR Lab reported a system to automatically plan surgical trajectories using preoperative CT and assist device placement by augmenting the fluoroscopic scene with planned trajectories.
ocedure that often requires long fluoroscopic exposure times and trial-and-error insertion attempts along narrow bone corridors of the pelvis. A recent paper by Runze Han (PhD student in Biomedical Engineering at Johns Hopkins University) and colleagues at the I-STAR Lab reported a system to automatically plan surgical trajectories using preoperative CT and assist device placement by augmenting the fluoroscopic scene with planned trajectories.
The system utilizes a pelvic shape and surgical trajectory atlas now available in the public domain at https://istar.jhu.edu/downloads/. The system does not require segmentation of the patient CT, operates without additional hardware (e.g., tracking system), and is consistent with common workflow in fluoroscopically guided procedures. Such a system has the potential to reduce operating time and radiation dose by minimizing trial-and-error in surgery.
The paper was published in Physics in Medicine and Biology, 2019.
Han R, Uneri A, Silva T D, Ketcha M, Goerres J, Vogt S, Kleinszig G, Osgood G, Siewerdsen J H, Atlas-Based Automatic Planning and 3D-2D Fluoroscopic Guidance in Pelvic Trauma Surgery. Phys. Med. Biol. 2019.https://doi.org/10.1088/1361-6560/ab1456
Mathematical Model for Image Registration Accuracy by Michael Ketcha et al., IEEE-TMI 2019
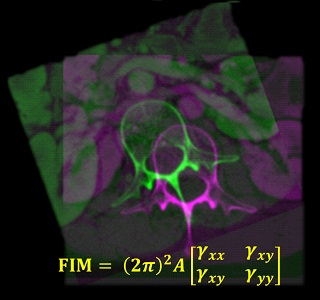 Accurate image registration is essential to the accuracy and precision of image-guided interventions. Despite the importance of this step, relatively little is known from a fundamental, mathematical basis of how image quality and other factors affects the accuracy of registration.
Accurate image registration is essential to the accuracy and precision of image-guided interventions. Despite the importance of this step, relatively little is known from a fundamental, mathematical basis of how image quality and other factors affects the accuracy of registration.
A recent paper by Michael Ketcha (PhD student in Biomedical Engineering at Johns Hopkins University) and colleagues at the I-STAR Lab reported a statistical model that incorporates image quality factors (noise and spatial resolution) as well as the deformation of soft-tissue structures on the performance of registration of rigid bone anatomy. The paper shows a generalized noise model that includes both quantum noise and deformed soft-tissue as noise sources, and the effects on registration accuracy are quantified for various 3D-3D (CT-to-CT) and 3D-2D (CT-to-radiograph) registration scenarios.
The model accurately predicted the impact of soft-tissue deformation on rigid registration error and provided a useful, general guide to selection of similarity metrics that are robust to the influence of deformation. Such a model provides an important theoretical basis for guiding the selection of image acquisition and processing parameters and informing the development of improved registration methods.
The paper was published in IEEE Transactions on Medical Imaging.
Ketcha, M. D., T. De Silva, R. Han, A. Uneri, G. Kleinszig, S. Vogt, and J.H. Siewerdsen. “A Statistical Model for Rigid Image Registration Performance: The Influence of Soft-Tissue Deformation as a Confounding Noise Source.” IEEE Trans. Med. Imag. (In Press).
I-STARs Earn Accolades at SPIE 2019
 The annual SPIE Medical Imaging Conference held in San Diego, California featured over 1,000 presentations including many from Johns Hopkins researchers on advances in medical imaging physics, analysis, and image-guided procedures. Three from Hopkins BME earned special distinction: Wenying Wang (BME PhD student advised by Dr. Web Stayman), Rohan Vijayan (BME PhD student advised by Dr. Siewerdsen), and Xiaoxuan ‘Esme’ Zhang (Research Scientist at the Carnegie Center for Surgical Innovation).
The annual SPIE Medical Imaging Conference held in San Diego, California featured over 1,000 presentations including many from Johns Hopkins researchers on advances in medical imaging physics, analysis, and image-guided procedures. Three from Hopkins BME earned special distinction: Wenying Wang (BME PhD student advised by Dr. Web Stayman), Rohan Vijayan (BME PhD student advised by Dr. Siewerdsen), and Xiaoxuan ‘Esme’ Zhang (Research Scientist at the Carnegie Center for Surgical Innovation).
PhD student Wenying Wang was the winner of the Robert Wagner Best Student Paper award. Wenying’s research aims to reduce dose and improve image quality in CT using a multiple aperture devices (MADs) for x-ray intensity modulation. Her work combines advanced instrumentation (precisely controlled multi-aperture collimators) with new methods for model-based image reconstruction (MBIR).
PhD student Rohan Vijayan was the finalist of the Robert Wagner Best Student Paper award. Rohan is developing an algorithm to automatically define the trajectory of instrumentation delivered in spine surgery. His work has produced an automated method based on atlas registration. His presentation at SPIE showed that the algorithm performed well in simulation, cadaver studies, and the first clinical studies. The method could streamline surgical procedures and improve the accuracy of robot-assisted screw placement.
Research Scientist Xiaoxuan Esme Zhang was the runner up of the Young Scientist Award. Esme is working on a CT image reconstruction algorithm that improves visualization of patient anatomy and reduces radiation exposure during image-guided procedures. Esme’s research not only shows the potential for improved image quality and reduced dose but also the ability to precisely visualize the placement of surgical instrumentation, which would be conventionally challenged by “metal artifacts.” Her work was the first to apply the algorithm in clinical studies, showing promising image quality results for patients undergoing spine surgery.
I-STAR Constellation of Talks at SPIE Medical Imaging 2019
20 February 2019 • 2:20 – 2:40 PM | Part of SPIE Medical Imaging
18 February 2019 • 9:20 – 9:40 AM | Part of SPIE Medical Imaging
19 February 2019 • 4:30 – 4:50 PM | Part of SPIE Medical Imaging
20 February 2019 • 11:30 – 11:50 AM | Part of SPIE Medical Imaging
19 February 2019 • 3:30 – 3:50 PM | Part of SPIE Medical Imaging
18 February 2019 • 1:20 – 1:40 PM | Part of SPIE Medical Imaging
21 February 2019 • 8:20 – 8:40 AM | Part of SPIE Medical Imaging
18 February 2019 • 3:20 – 3:40 PM | Part of SPIE Medical Imaging
19 February 2019 • 2:00 – 2:20 PM | Part of SPIE Medical Imaging
20 February 2019 • 10:10 – 10:30 AM | Part of SPIE Medical Imaging
17 February 2019 • 8:40 – 9:00 AM | Part of SPIE Medical Imaging
17 February 2019 • 8:00 – 8:20 AM | Part of SPIE Medical Imaging
17 February 2019 • 8:20 – 8:40 AM | Part of SPIE Medical Imaging
Dr. Francis Creighton
Dr. Siewerdsen among the BME Pioneers — Medical Imaging
 New medical imaging systems, algorithms, and applications are shaping the future of image-guided interventions and diagnostic radiology. In this video, Dr. Siewerdsen – among the BME Pioneers in medical imaging – describes new imaging technologies that are among the most vibrant areas of biomedical imaging research, offering major impact in translation to clinical use. Watch Jeff’s “Pioneer” YouTube video at the following link and other BME Pioneers here.
New medical imaging systems, algorithms, and applications are shaping the future of image-guided interventions and diagnostic radiology. In this video, Dr. Siewerdsen – among the BME Pioneers in medical imaging – describes new imaging technologies that are among the most vibrant areas of biomedical imaging research, offering major impact in translation to clinical use. Watch Jeff’s “Pioneer” YouTube video at the following link and other BME Pioneers here.
Statistical Weights for Model-Based Reconstruction in Cone-Beam CT with Electronic Noise and Dual-Gain Detector Readout
A recent paper by Pengwei  Wu (PhD student in Biomedical Engineering at Johns Hopkins University) and colleagues at the I-STAR Lab reported a penalized weighted least-squares (PWLS) method for CBCT image reconstruction with a system model that includes the electronic noise characteristics of FPDs, including systems with dynamic-gain or dual-gain (DG) readout in which the electronic noise is spatially varying.
Wu (PhD student in Biomedical Engineering at Johns Hopkins University) and colleagues at the I-STAR Lab reported a penalized weighted least-squares (PWLS) method for CBCT image reconstruction with a system model that includes the electronic noise characteristics of FPDs, including systems with dynamic-gain or dual-gain (DG) readout in which the electronic noise is spatially varying.
The methods were tested in phantom studies designed to stress DG readout characteristics and translated to a clinical study for CBCT of patients with head traumas. The PWLS^DG method demonstrated superior noise-resolution tradeoffs compared to filtered back-projection (FBP) and conventional PWLS. Statistical weights in PWLS were modified to account for the contribution of the electronic noise (algorithm denoted PWLS^DG), and the method was combined with a certainty-based approach that improves the homogeneity of spatial resolution (algorithm denoted PWLS_Cert^DG).
These findings were confirmed in clinical studies, which showed ~20% variance reduction in peripheral regions of the brain, potentially improving visual image quality in detection of epidural and/or subdural intracranial hemorrhage.
The results are consistent with the general notion that incorporating a more accurate system model improves performance in optimization-based statistical CBCT reconstruction – in this case, a more accurate model for (spatially varying) electronic noise to improve detectability of low-contrast lesions.
Citation Pengwei Wu, Joseph Webster Stayman, Alejandro Sisniega, Wojciech Zbijewski, David Foos, Xiaohui Wang, Nafi Aygun, Robert Stevens and Jeffrey H. Siewerdsen.
The paper was published in Physics in Medicine and Biology, 2018. Link
Statistical Weights for Model-Based Reconstruction in Cone-Beam CT with Electronic Noise and Dual-Gain Detector Readout. Physics in Medicine & Biology 2018 November 14. doi: 10.1088/1361-6560/aaf0b4
#div id=”elementor-tab-title-1272″
Mobile C‐Arm with a CMOS Detector: Technical Assessment of Fluoroscopy and Cone‐Beam CT Imaging Performance

A recent paper by Niral M. Sheth and colleagues at the I-STAR Lab investigates the performance of a low-noise, high-resolution CMOS flat-panel x-ray detector for C-arm fluoroscopy and cone-beam CT (CBCT). A pair of mobile C-arms was used in the work – one outfitted with a conventional detector based on a hydrogenated amorphous silicon (a-Si:H) array of sensors and thin-film transistors (TFTs) and the other with a CMOS detector offering finer pixel pitch, faster readout, and lower electronic noise. The study included a quantitative technical assessment of 2D and 3D imaging performance as well as realistic imaging scenarios in interventional radiology, orthopaedic surgery, vascular surgery, and neurosurgery. Both detectors incorporated a crystalline CsI:Tl scintillator. The benefits of low electronic noise and improved spatial resolution were especially evident under low-dose imaging conditions and for imaging tasks involving high spatial frequencies – for example, visualization of stents and other interventional devices.
The quantitative technical assessment included evaluation of 2D imaging performance pertinent to fluoroscopic imaging (dark noise, gain, linearity, image lag, modulation transfer function (MTF), noise-power spectrum (NPS), and detective quantum efficiency (DQE)) as well as 3D imaging performance in CBCT (image uniformity, 3D MTF, 3D NPS, 3D noise-equivalent quanta (NEQ)). Realistic imaging scenarios were emulated using cadaver specimens and an array of interventional devices and instrumentation for interventional radiology (lines and catheters), orthopaedic surgery (K-wires and screws), vascular surgery (balloons and stents), and neurosurgery (intracranial shunts and aneurysm coils). The qualitative assessment of resulting images helped to confirm and interpret the technical findings, including the conditions under which the two detectors provided images that appeared functionally equivalent and those for which CMOS performance advantages were visually evident with respect to a particular clinical task.
Citation:
Niral M. Sheth, Wojciech Zbijewski, Matthew W. Jacobson, Godwin Abiola, Gerhard Kleinszig, Sebastian Vogt, Stefan Soellradl, Jens Bialkowski, William S. Anderson, Clifford R. Weiss, Greg M. Osgood, and Jeffrey H. Siewerdsen.
The paper was published in the Medical Physics journal, 2018. Link
Mobile C‐Arm with a CMOS detector: Technical assessment of fluoroscopy and Cone‐Beam CT imaging performance Med Phy. 2018 Oct 19. doi: 10.1002/mp.13244.
Clinical Evaluation of the LevelCheck Algorithm for Decision Support in Spine Surgery
Ali Uneri’s Paper on High-Quality 3D Imaging on the O-Arm for Image-Guided Surgery

A paper by Dr. Ali Uneri andcoauthors investigates 3D image quality and potential for radiation dose reduction using iterative model-based image reconstruction (MBIR). His work includes a comprehensive analysis of dosimetry for standard imaging protocols on the Medtronic O-arm and uses MBIR (penalized likelihood estimation with a Huber penalty) to achieve improved soft-tissue contrast resolution and dose reduction. The MBIR methods were found to increase soft-tissue contrast-to-noise ratio (CNR) by nearly 50% compared to conventional filtered backprojection without loss of spatial resolution.
Using custom low-dose protocols, the performance of MBIR was even higher, showing nearly a factor of 2 increase in CNR comparead to FBP when dose was reduced by a factor of 2 from standard clinical protocols. The work demonstrates the potential of MBIR for improving image quality and reducing dose in image-guided surgery and has motivated translation of the methodology to clinical studies, now underway.
The paper was published in the Medical Physics journal – link – with presentation of the work at the SPIE Medical Imaging conference, 2018.
Paper by Pengwei Wu et al. Uses Reconstruction-of-Difference (RoD) for 3D Angiography
Fast, accurate assessment of blood flow and neurovascular structures is essential to effective treatment of stroke. The front-line technology for imaging vascular occlusion or hemorrhage is CT. Mobile systems for cone-beam CT (CBCT) could provide advantages for timely assessment at the point of care.
A recent paper by Pengwei Wu (PhD student in Biomedical Engineering at Johns Hopkins University) published in the journal of Physics in Medicine and Biology applies a new 3D image reconstruction technique called “Reconstruction of Difference” (RoD) to allow accurate 3D angiographic imaging in CBCT. With coauthors from the I-STAR Lab and Departments of Radiology and Neurology at Johns Hopkins Hospital, the RoD method helps to overcome challenges arising from the relatively slow rotation speed and data sparsity (fewer projections) in CBCT.
With initial results reported in the Master’s Dissertation by coauthor Michael Mow, the paper reports a number of important findings. First is a fast 3D digital simulation framework allowing efficient simulation of bloodflow in the brain, overcoming conventional bottlenecks of brute-force volumetric forward projection. Pengwei used the simulation framework to show the advantages of RoD over conventional filtered backprojection (FBP) and penalized likelihood (PL) reconstruction methods over a broad range of imaging conditions. He also used a recently developed prototype CBCT scanner for high-quality imaging of the brain to test the methodology in a phantom under realistic imaging conditions.The RoD method improved the accuracy of 3D angiographic images by ~50% compared to FBP and by ~30% compared to PL, and the studies identified optimal scan protocols for the RoD approach to balance tradeoffs among scan speed and data sparsity. An example scan protocol showing good results with RoD involved just 128 projections acquired over a semicircular (pi + fan) orbit in 8.5 seconds. The results point to the feasibility of 3D angiography on low-cost, portable CBCT systems enabled by advanced 3D image reconstruction methods such as RoD. Future work includes optimization of the contrast injection protocols and investigation of CBCT perfusion imaging.
The full paper can be downloaded here.
Pengwei Wu, Joseph Webster Stayman, Michael Mow, Wojciech Zbijewski, Alejandro Sisniega, Nafi Aygun, Robert Stevens, David H Foos, Xiaohui Wang, and Jeffrey H Siewerdsen, “Reconstruction-of-difference (RoD) imaging for cone-beam CT neuro-angiography,” Phys Med Biol (in press; available online May 3, 2018).
Open-Source Tools for Image-Guided Surgery

A large library of rigid-body marker designs for research in surgical navigation is now available HERE. – version 1.0 of the Dynamic Reference Frame (DRF) library. Alisa Brown (Department of Biomedical Engineering, Johns Hopkins University) developed the library with support from the STAR Program for Undergraduate Research at JHU. The DRF library includes 10 groups of rigid-body markers – each with up to 10 tools each – compatible with infrared tracking systems from Northern Digial (NDI). A multitude of distinct, simultaneously trackable DRF designs are included in he library, along with CAD files suitable to 3D printing and tool definition files. The tools are for research purposes only.
The library is available on the I-STAR Downloads Page.
A complete technical description of the library is provided in the journal paper published in the Journal of Medical Imaging, February 2018.
Alisa J. V. Brown, Ali Uneri, Tharindu S. De Silva, Amir Manbachi, and Jeffrey H. Siewerdsen, “Design and validation of an open-source library of dynamic reference frames for research and education in optical tracking,” J. of Medical Imaging, 5(2), 021215 (2018). doi:10.1117/1.JMI.5.2.021215
The I-STARs Align at SPIE Medical Imaging 2018
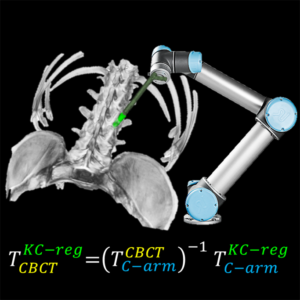
The annual SPIE Medical Imaging Symposium held in February 2018 features 14 talks from the I-STAR Lab and collaborators in Biomedical Engineering, Radiology, Neurosurgery, and Orthopaedic Surgery at Johns Hopkins University.
Image-Guided Surgery
Selected for a distinguished presentation in the Image-Guided Interventions conference, Thomas Yi, a graduate of Hopkins BME mentored by Dr. Ali Uneri presents his work on x-ray-guided robot-assisted spine surgery. Thomas’ research uses 3D-2D registration to automatically position a robotic drill guide for high-precision placement of spinal pedicle screws. His work offers an advance beyond conventional approaches to robotic assistance in a way that is more accurate in the presence of deforming anatomy and operates without additional optical markers and surgical trackers.
Alisa Brown’s work was also selected for a distinguished presentation in Image-Guided Interventions. Alisa will report on the design and validation of a large, open-source library of rigid-body markers for surgical navigation. Her work yielded a library of dynamic reference frames that can be produced using a 3D printer and facilitates research and development in surgical navigation using multiple tracked tools.
Runze Han, a PhD student in Hopkins Biomedical Engineering supervised by Dr. Siewerdsen, describes a method for automatically planning surgical approach in pelvic trauma surgery. Using a 3D atlas of pelvic shapes and reference paths representing ideal surgical trajectories in trauma fixation, the method registers the atlas information to a patient’s CT image in a manner that provides automatic planning and visualization of ideal trajectories. Combined with intraoperative fluoroscopy or cone-beam CT, the method provides a means for guidance and quality assurance of K-wire placement in trauma surgery.
Niral Sheth, a Research Scientist at the Carnegie Center for Surgical Innovation, reports on the imaging performance of an intraoperative C-arm incorporating a high-performance CMOS x-ray detector. The new detector offers higher levels of spatial resolution, lower electronic noise, and higher frame rate. Niral measured the improvements in resolution, noise, and NEQ in fluoroscopy and cone-beam CT and validated the findings in cadaver studies in collaboration with the Department of Radiology, Neurosurgery, and Orthopaedic Surgery.
3D Image Reconstruction:
Ali Uneri, a postdoctoral fellow at the Carnegie Center for Surgical Innovation, reports findings from his work using model-based image reconstruction (MBIR) on the Medtronic O-arm. The iterative reconstruction methods are shown to improve soft-tissue image quality and reduce radiation dose in image-guided surgery. Combined with novel methods for deformable 3D2D and 3D3D image registration, his work promises to expand the availability of high-precision surgical techniques to new clinical applications.
Pengwei Wu, a PhD student in Hopkins Biomedical Engineering supervised by Dr. Siewerdsen, reports on the Reconstruction-of-Difference (RoD) algorithm for cone-beam CT neuro-angiography. Pengwei’s work shows how the RoD 3D image reconstruction method is more robust than conventional approaches under conditions of data sparsity or inconsistency, offering to expand the utility of cone-beam CT in angiographic applications.
Wenying Wang, a PhD student in Hopkins Biomedical Engineering supervised by Dr. Web Stayman in the AIAI Lab, reports a model for spatial resolution and noise in flat-panel detector cone-beam CT images reconstructed using penalized likelihood estimation. Wenying’s work yields predictive models that accurately describe the modulation transfer function (MTF) and noise-power spectrum (NPS) for iterative reconstruction methods yielding non-stationary signal and noise characteristics.
Hao Zhang, a postdoctoral fellow in the AIAI Lab, reports a method for prospectively selecting key parameters in prior-image-based 3D image reconstruction in a manner that reliably controls the influence of new and prior image information in MBIR. Hao’s work offers to improve image quality and reduce dose in longitudinal imaging / screening of lung cancer, and it provides an important advance in stable, reliable reconstruction methods using prior image information.
Diagnostic Imaging:
Qian Cao, a PhD student in Hopkins Biomedical Engineering supervised by Dr. Wojciech Zbijewski, reports on the high-resolution characteristics of a CMOS detector in cone-beam CT for imaging of bone micro-architecture. Qian’s work shows how the improved x-ray detector – combined with advanced image reconstruction methods – advances the performance of CBCT to a level sufficient for quantitative assessment of fine subchondral bone structure.
Alejandro Sisniega, a Research Associate faculty member at the I-STAR Lab, reports on the influence of curved detector designs in compact geometry CBCT systems, including the importance of antiscatter grid selection and bowtie filter design. Alex’s work shows that CBCT systems with a very compact form can be achieved while mitigating high levels of x-ray scatter – with image quality suitable for imaging of low-contrast intracranial hemorrhage in traumatic brain injury.
Michael Brehler, a postdoctoral fellow at the I-STAR Lab supervised by Dr. Wojciech Zbijewski, reports on methods for quantitative analysis of trabecular bone structure in high-resolution cone-beam CT. Michael’s work shows that optimized segmentation methods can yield analysis of bone structure in clinical CBCT images with a high level of correlation to micro-CT.
Image Registration:
Michael Ketcha, a PhD student in Hopkins Biomedical Engineering supervised by Dr. Siewerdsen, describes a mathematical model for image registration performance that includes not only the influence of image quality (noise and resolution) but also the confounding influence of soft-tissue deformation. With analogues in statistical decision theory, Michael’s work reveals a sophisticated analytical framework for understanding the performance of various similarity metrics used in image 2D or 3D image registration and analyzing the lower bound in registration performance.
Benjamin Ramsay, an undergraduate in Hopkins BME, reports a variation on atlas-based registration in which sub-atlases are used in a series of stages according to similarity in principal component analysis to guide more accurate deformable registration. Using an iterative sub-atlas approach, Ben’s work shows how active shape models and PCA can be used to make better use of limited atlas datasets and improve computational speed.
Tharindu De Silva, a postdoctoral fellow at the Carnegie Center for Surgical Innovation, reports on a fast slice-to-volume image registration method for ultrasound imaging in spinal interventions. His work exploits Haar feature analysis for real-time registration performance. By combining the method with 3D registration of ultrasound to preoperative MRI, Tharindu’s work reveals a method for real-time image-based navigation that could improve the precision and safety of needle injections in the spine.
Multi-Source Cone-Beam CT Improves 3D Image Quality and FOV
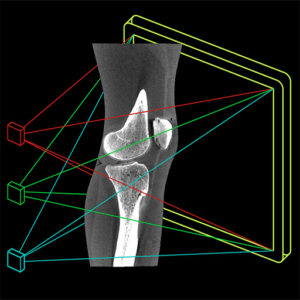
A recent paper by G. Gang, W. Zbijewski, M. Mahesh, and colleagues at the I-STAR Lab investigates the image quality, dose, and 3D sampling characteristics of a multi-source cone-beam CT system, earning Editor’s Pick in the Medical Physics journal:
G. Gang et al., “Image quality and dose for a multisource cone-beam CT extremity scanner,” Med Phys 45(1): 144-155 (2018). (free PDF)
The novel x-ray source arrangement was implemented by collaborators at Carestream Health (Rochester NY) in a prototype scanner developed for high-quality cone-beam CT of the extremities for musculoskeletal radiology and orthopaedic imaging. The scanner was developed in academic-industry partnership (see, for example, earlier papers by Prakash, Zbijewski, and Carrino).
The multi-source configuration resulted in a number of positive improvements in imaging performance. For example, the longitudinal field of view (FOV) was increased to ~30 cm length, providing better coverage with more uniform signal and noise characteristics throughout. Cone-beam artifacts were reduced overall due to improved 3D sampling – visually evident as reduced streaks from structures oriented parallel to the source plane (such as articular surfaces) and a reduced null cone in 3D Fourier space. Moreover, the volumetric dose distribution was more evenly distributed for the multi-source configuration. The three-source configuration also permits novel dual-energy CBCT imaging techniques in which the top and bottom source are operated at a beam energy (and added filtration) different from that of the middle source – giving a central volumetric region in which the beams overlap and within which dual-energy material decomposition can be performed.
The paper was selected for Editor’s Choice designation, recognizing papers that reflect the highest quality and potential scientific impact. In addition to being highlighted as an Editors’ Choice paper, manuscripts selected for this distinction are published as freely-available articles at no cost (pdf).
Task-Driven Imaging: Grace Gang’s Paper Puts Photons Where They Count

“Task-driven imaging,” says Grace Gang, “means that you first specify what you want to see – the task< – and then drive the image acquisition and reconstruction process in way that maximizes performance of the task.”
A new paper by Gang, Siewerdsen, and Stayman develops a mathematical framework for driving the x-ray tube current (mA) modulation, optimizing the spatial distribution of x-ray fluence in each projection, and setting the image reconstruction parameters in a manner that maximizes task-based imaging performance. The paper appears in a special issue of IEEE-TMI on Low-Dose CT.
Using models of local spatial resolution (MTF) and noise (NPS) for iterative reconstruction (penalized likelihood estimation, PLE) established in her previous work, the paper uncovers a number of new findings with important implications for reducing dose and improving image quality in CT. Among these is an exciting finding that challenges conventional paradigms of mA modulation. In body CT, for example, conventional methods based on filtered backprojection (FBP) tend to increase tube current in lateral views, where attenuation is highest, to increase detector signal and “make bad views better.” For PLE, however, Gang’s work shows that imaging performance is improved instead by increasing mA in the posterior-anterior views (and reducing mA in lateral views) to “make good views better,” since PLE weights the projection data in proportion to their fidelity (noise level) in the reconstruction process.
The paper goes beyond mA modulation and includes optimization of the spatial distribution of x-rays in each view – as Dr. Stayman says, “putting photons where they count.” In this respect, the task-driven method prescribes increased fluence through the central, more highly attenuating regions of the patient to yield a relatively constant x-ray fluence incident on the detector. As a result, the optimal reconstruction parameters (namely, the statistical weighting terms) are relatively constant across the data, and the resulting image exhibits more uniform resolution and noise throughout.
The paper also tackles the question of multiple imaging tasks – an important question often posed with respect to task-based imaging paradigms – namely, how to optimize the imaging process if there is more than one task? or more than one location of the task? or if one cannot say for certain what the task is? Gang adopts a maxi-min approach that offers a solution: given a plurality of tasks (varying in their spatial location, spatial frequency distribution, etc.), maximize the minimum detectability throughout the image for all tasks. Thus, the optimal acquisition and reconstruction process is that which yields the least worst performance overall, and the principle can be extended to a general description of all possible locations and/or all possible tasks.
The IEEE-TMI paper is available here, with related work including:
– Task-based detectability in CT…
– Task-driven image acquisition and reconstruction…
– Modeling and control of nonstationary noise…
– Fluence-Field Modulated X-ray CT…
Dr. Siewerdsen at the Nobel Forum in Stockholm: Advances in Image-Guided Surgery

On November 16, 2017, Dr. Jeff Siewerdsen gave a lecture at the Nobel Forum in Stockholm entitled Advances in 3D Imaging and Registration for Image-Guided Interventions together with Dr. Nicholas Theodore, who discussed advances in Robot-Assisted Surgery. Dr. Siewerdsen discussed emerging areas of 3D imaging, image registration, and data-intensive approaches to improving the precision and safety of surgery.
His lecture described how advances in interventional C-arms and 3D image reconstruction methods can improve image quality and provide a valuable basis for Operating Room Quality Assurance, or ORQA. He also described how image registration approaches provide not only a means for target localization and guidance but also a basis for emerging data-intensive analytics to link image information with predictive models for surgical outcome. Thanks to the Nobel Forum, the Stockholm County Council, the KTH Royal Institute of Technology, the Karolinska Institute, and Dr. Mats Danielsson for hosting the lecture and for tremendous hospitality. Dr. Siewerdsen’s lecture can be viewed at
https://www.youtube.com/watch?v=i7mqYjZQX1Q.
I-STAR Research at the Big Show: RSNA 2017
Eight presentations from the I-STAR Lab at the 2017 annual meeting of the RSNA (Chicago, IL) include the latest research on cone-beam CT, image registration, and analysis.
Dr. Jeff Siewerdsen‘s seminar (E352, Sunday 11/26 at 2:00 pm) provides an update and continuing education review of “Open Gantry CT Systems,” including C-arms for 3D image-guided interventions and novel emerging platforms for high-quality cone-beam CT at the point of care. PDF handouts from Dr. Siewerdsen’s presentation are available here.
Qian Cao‘s presentation (PHS-MOB, Monday 11/27 at 12:45 pm) is on the topic of “High-Resolution Extremity Cone-Beam CT with a CMOS X-Ray Detector,” showing how an imaging physics model was used to optimize a new imaging system under development for high-resolution imaging of bone health.
Gaurav Thawait gives two oral presentations – the first (E451B, Monday 11/27 at 3:10 pm) on “Motion Compensation in Cone-Beam CT,” showing a novel auto-focus method to overcome even sub-mm involuntary motion in high-resolution imaging for MSK radiology, and the second (S404AB, Monday 11/27 at 3:50 pm) on the use of CBCT for “Evaluation of Bone Erosions in Rheumatoid Arthritis,” including results from a recent clinical study.
Alejandro Sisniega‘s talk (S403A, Monday 11/27 at 3:40 pm) shows how “Flat and Curved System Geometries” pose important considerations for x-ray scatter, dose, and the design of novel compact imaging systems.
Tharindu De Silva presents (S403A, Tuesday 11/28 at 3:30 pm) on the topic of “Free-Hand Ultrasound Registration to MRI” for high-precision guidance of spinal intervention and pain management, showing a novel approach for image registration that leverages a physics model for ultrasound image formation to drive accurate alignment with preoperative MRI.
Wojciech Zbiweski‘s seminar (N229, Wednesday 11/20 at 9:00 am) covers the latest advances in CT imaging in MSK Radiology and Orthopaedics, including novel cone-beam CT systems developed for high-resolution, weight-bearing imaging as well as dual-energy imaging and methods for analyzing morphological structure at both macroscopic and microscopic levels of detail.
Finally, Michael Brehler provides a talk (S403B, Thursday 11/30 at 10:40 am) on the topic of “Automatic Algorithm For Joint Morphology Measurements In Volumetric Musculoskeletal Imaging,” detailing shape analysis and atlas-based methods for automatically computing important metrics of joint morphology in images of the weight-bearing knee.
Distinguished Lecture: David Jaffray’s Insight on Complexity and Nonlinear Events in Medical Technology

Dr. David Jaffray delivered the Distinguished Lecture in Biomedical Engineering at Johns Hopkins Hospital on November 7, 2017. Dr. Jaffray is Professor of Radiation Oncology, Medical Biophysics, and Biomedical Engineering at the University of Toronto and is Head of Radiation Physics, Director of the Techna Institute, and Executive Vice-President of Technology and Innovation at the University Health Network (Toronto ON). Jaffray led the team that developed the first systems for cone-beam CT guidance of radiation therapy, and he continues to lead technology innovation in broad sectors of imaging, radiation therapy, and information technology.
Dr. Jaffray’s lecture was held in historic Hurd Hall at Johns Hopkins Hospital, entitled “From Complexity to Industrialized Medicine: Non-Linear Events in Man’s Affair with Technology.” Jaffray argued that complexity increases in proportion to the ever-increasing density and conglomeration of technology employed within a given process – for example, healthcare delivery – an unsustainable trend that eventually sparks “non-linear” innovation to bury complexity and restore simplicity, efficiency, and effectiveness of the process. Noting examples spanning over a a century of industrialization / technology and communication / computing, he described the imminent need for readiness in our healthcare delivery system for such non-linear innovations likely to emerge in the decade ahead.
Jaffray also described how clinical needs for improved patient safety can spark technological innovations that in turn advance capabilities for new forms of medical diagnosis and intervention, which in turn spark new hypotheses and scientific discovery – a cycle of clinical practice, quality improvement, and scientific advancement that speaks to the importance of close collaboration among clinicians and scientists / engineers. He noted several examples from image-guided radiation therapy, where image guidance systems have helped to reduce or eliminate patient setup errors, reducing uncertainties and enabling investigation of new hypotheses on physiological factors of tumor response (for example, hypoxia and interstitial pressure) and driving new treatment techniques to improve tumor control.
Finally, Dr. Jaffray conveyed a vision for data science integrated with healthcare delivery – a rapidly approaching future in which the radiology reading room, the surgical theater – indeed the hospital, if not the healthcare system as a whole – could (or must) embrace processes and scientific expertise by which data relating to each patient is continuously captured, curated, and learned in order to improve and streamline delivery and anticipate imminent needs. By analogy to the Star Trek Enterprise, Jaffray described the hospital as a learning machine within which Science and Engineering are integral to “boldly go” where no one has gone before.
The Distinguished Lecture in BME was hosted by Dr. Jeff Siewerdsen, with thanks to Dr. Warren Grayson for organizing the lecture series and to Ms. Joyce Bankert and Mrs. MJ Bostic for valuable assistance.
Task-Based CT Image Reconstruction: Paper by Hao Dang et al.
An image is almost always formed for a specific purpose – or “task” – and models of image quality help us determine the image acquisition, reconstruction, and processing techniques to optimize task performance. For example, to resolve fine details, one could use a finer focal spot and use a high-pass reconstruction filter, whereas to detect subtle low-contrast features, one may need to increase the dose and/or use a smoother filter. The tradeoffs among the numerous factors that govern imaging performance introduce a complex interplay that can be described by physical / mathematical models of task-based image quality, and the need to accomplish one or more specific imaging tasks presents an important optimization problem in the development of new imaging systems.
In a paper published in the journal – Physics in Medicine and Biology – Hao Dang and coauthors present a method that combines a model for task-based imaging performance with statistical iterative 3D image reconstruction methods, taking task-based performance as the objective function in optimizing the regularization strength in penalized likelihood estimation. Moreover, Hao’s method recognizes the spatial dependence (“non-stationarity”) of the spatial resolution and image to select regularization strength separately throughout the image to identify an optimum at every point in the image, yielding an image that is optimal to the task at every location. The paper represents the final chapter of Hao Dang’s PhD dissertation in Biomedical Engineering at Johns Hopkins University.
Hao applied the method to the task of detecting intracranial hemorrhage with a recently developed cone-beam CT system for point-of-care imaging in the Neurological Critical Care Unit (NCCU). The system could bring high-quality imaging to the bedside in caring for critically ill patients for whom transport to CT scanner can introduce unacceptable risks. The prototype cone-beam CT scanner is portable and could be brought to the patient. Hao’s method for task-based image reconstruction was shown to increase image quality compared to conventional approaches, especially under conditions of low dose and in particular regions of the brain – for example, in deep regions of the skull base, where conventional reconstruction methods can be challenged by high image noise or over-smoothing of the data. The task-driven image reconstruction method was able to better resolve low-contrast simulated brain hemorrhage and is being translated to first clinical studies at Johns Hopkins University.
The paper is available at Pub Med and the journal Physics in Medicine and Biology.
Coauthors include collaborators at Hopkins BME (Dr. Web Stayman, Dr. Jennifer Xu, Dr. Wojciech Zbijewski, Dr. Alejandro Sisniega, Mr. Michael Mow, and Dr. Jeff Siewerdsen), clinical collaborators in Neuroradiology and Neurology (Dr. Nafi Aygun and Dr. Vassilis Koliatsos), and collaborators at Carestream Health (Dr. Xiaohui Wang and Dr. David Foos).
Welcome Dr. Nick Theodore, Co-Director of the Carnegie Center for Surgical Innovation

The I-STAR Lab welcomes Dr. Nick Theodore as Co-Director for the Carnegie Center for Surgical Innovation. Dr. Theodore is the Donlin M. Long Professor of Neurosurgery at Johns Hopkins University and directs the Johns Hopkins Neurosurgical Spine Center. An internationally recognized expert and innovator in minimally invasive spine surgery and surgical robotics, Dr. Theodore has authored ~200 scientific articles and holds numerous patents for breakthrough devices and procedures for novel treatments of brain and spinal cord injury. He is also an active mentor of surgical trainees and biomedical engineers, including projects at the Carnegie Center, I-STAR Lab, and CBID Program. Research underway includes the development of methods for high-quality, low-dose 3D imaging in the OR, novel surgical guidance methods, advanced, surgical robotics, intraoperative assessment of spinal alignment, and “big data” approaches to improving patient outcomes in spine surgery. Dr. Theodore joins Dr. Siewerdsen in leading the Carnegie Center mission for multi-disciplinary, collaborative research, education, and translation of breakthrough innovations in surgery. Welcome, Nick!
Image Registration Performance and Image Quality: Ketcha’s Model Provides a Link
Intuitively, the task of registering two images (for example, aligning a preoperative CT image with an intraoperative radiograph or cone-beam CT) must depend on the quality of the images. And it stands to reason that the accuracy of registration will improve with the quality of those images. But what is the connection – exactly – and what are the image quality factors that govern registration accuracy? Spatial resolution? Noise? And are the limits in visual image quality (for example, a low-dose image for which a feature is no longer visible) the same as the lower limits in registration performance?
These questions are at the heart of a new paper by Michael Ketcha and co-authors at the I-STAR Lab in Biomedical Engineering at Johns Hopkins University, yielding a theoretical model that links image registration performance with image quality. Models for each have been established in previous work, but the connection between the two has not been well formulated. For example, Michael Fitzpatrick and colleagues established a statistical framework for understanding Target Registration Error (TRE), governed by the Fiducial Localization Error (FLE), Fiducial Registration Error (FRE), and the spatial distribution of fiducials with respect to a target point. Meanwhile, Ian Cunningham and colleagues produced a cascaded systems model for image quality describing the propagation of signal and noise – providing the basis for image quality models describing the tradeoffs among spatial resolution, noise, and dose in flat-panel x-ray detectors, tomosynthesis, and cone-beam CT. Such theoretical models have been invaluable to the development of new imaging and image guidance systems over the last two decades, but the connection between the two – HOW IMAGE QUALITY AFFECTS REGISTRATION ACCURACY – has remained largely unanswered.
Michael Ketcha’s paper published in IEEE-TMI in July 2017 derives the Cramer-Rao lower bound (CRLB) for registration accuracy in a manner that reveals the underlying dependencies on spatial resolution and image noise. By analyzing the CRLB as a function of dose, the work sheds light on the low-dose limits of image registration in a manner that could help reduce dose in image-guided interventions, where the task is often one of registration rather than visual detection.
The analysis considers the CRLB as the inverse of the Fisher Information Matrix (FIM) and derives the relationship on two main factors. First is the image noise, which depends on dose and may be different in the two images. Second is the power of (sum of squared) image gradients, which is governed by the contrast and frequency content of the subject. The FIM is thereby related to factors of image noise, resolution, and dose in a manner that permits analysis of the CRLB for a variety of scenarios – including registration of low-contrast soft tissues, high-contrast bone structures, and the effect of image smoothing to improve registration performance.
The work is analogous to widespread efforts to identify low-dose limits of visual detectability via models of imaging task. In image-guided interventions, however, the task of registration is often as important (or more important) as the task of visualization, allowing preoperative images and planning information to be accurately aligned with the patient at the time of treatment. Previous experiments by Uneri et al. showed that registration algorithms can perform well at dose levels below that which would normally be considered to yield a visually acceptable image — effects that are borne out by Ketcha’s analysis.
Motion Correction for High-Resolution Cone-Beam CT: Paper by Sisniega et al.
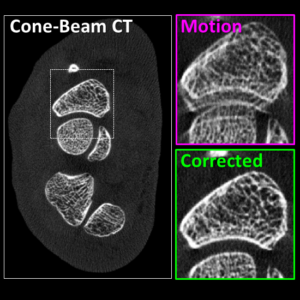
A paper published by Dr. Alejandro Sisniega (Research Associate, Department of Biomedical Engineering) and colleagues at the I-STAR Lab describes a new method for correcting patient motion in cone-beam CT (CBCT). Because CBCT often involves scan times >10 sec (for example, 20-30 sec common in extremity imaging and up to 60 sec in image-guided procedures), patient motion during the scan can result in significant degradation of image quality.
Even a few mm of motion can confound the visibility of subtle image features. A variety of methods have been reported in recent years to correct motion artifacts. Dr. Sisniega’s approach involves a purely image-based solution that does not require external motion tracking devices or prior images of the patient. Instead, the patient motion trajectory is derived directly from the image data using a 3D “auto-focus” method that optimizes sharpness of the resulting 3D image. Sisniega evaluated a number of possible sharpness metrics – including total variation and entropy – and showed gradient variance to perform best overall.
The method uses one or more volumes of interest (VOIs) within which motion can be assumed to follow a rigid trajectory – for example a bone structure – and can support multiple VOIs to independently solve for patient motion across the entire image, even in the presence of complex deformation. For example, in CBCT of the extremities, the method was shown to perform well in images of the knee using 2 VOIs – one for the distal femur and one for the proximal tibia (and optionally, a third for the patella). The method was rigorously evaluated in phantom studies on a CBCT benchtop, showing the ability to recover spatial resolution both in small motions (~0.5 – 1 mm perturbations) and large motions (>10 mm motion during the scan). The algorithm was then tested in clinical studies on an extremity CBCT system in the Department of Radiology and Johns Hopkins Hospital. Cases exhibiting significant motion artifacts were identified in retrospective review, and the algorithm was shown to reliably eliminate artifacts and recover spatial resolution sufficient for visualizing the joint space, subchondral trabecular bone, and surrounding soft-tissue features, including tendons, ligaments, and cartilage.
The motion correction algorithm is now proving its merit in applications within and beyond musculoskeletal extremity imaging, including CBCT of head trauma and C-arm CBCT, which can also involve long scan times and challenging motion artifacts. In addition to restoring spatial resolution in CBCT of bone morphology, ongoing work shows the algorithm to be important in recovering low-contrast visibility of soft tissues as well. Dr. Sisniega is extending the method to handle complex deformation of soft-tissue structures in the abdomen – tackling one of the major challenges to CBCT image quality in image-guided interventions.
Full details of the algorithm and experimental studies can be found in the paper published in the journal of Physics in Medicine and Biology (2017 May 7;62(9):3712-3734. doi: 10.1088/1361-6560/aa6869).
Imaging for Safer Surgery – Michael Ketcha’s Algorithm for Targeting the Deformed Spine
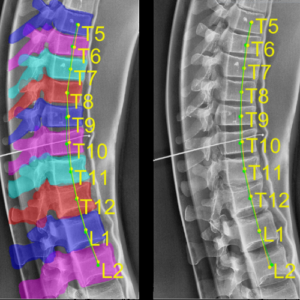
A recent paper by Michael Ketcha and coauthors at the I-STAR Lab reports a method for accurately targeting vertebrae in surgery under conditions of strong spinal deformation. Previous research showed a method by which target vertebrae defined in preoperative CT or MRI can be accurately localized in intraoperative radiographs via the LevelCheck algorithm for 3D-2D image registration. While LevelCheck was shown to provide accurate localization over a broad range of clinical conditions, the underlying registration model is rigid, meaning that it does not account for strong changes in spinal curvature occurring between the preoperative image and the intraoperative scene. Such deformation can be considerable, for example, in scenarios where preoperative images are acquired with the patient in a prone position, but intraoperative images are acquired with the patient laying supine – and sometimes kyphosed or lordosed to improve surgical access. Ketcha’s algorithm extends the utility of the LevelCheck algorithm to such scenarios by developing a “multi-scale” registration process – called msLevelCheck. The multi-scale method begins with a (rigid) LevelCheck initialization and proceeds in a region-of-interest pyramid to successively smaller segments and, in the final stage, about individual vertebrae. The resulting effect is a deformable transformation of vertebral labels from the preoperative 3D image to the intraoperative 2D image. Ketcha’s paper shows the algorithm to be accurate and robust in laboratory phantom studies across a broad range of spinal curvature and includes the first clinical testing of the msLevelCheck approach in images of actual spine surgery patients.
Previous research to address such deformation relies on segmentation of structures in the 3D preoperative image – a potentially time-consuming process that introduces additional workflow and potential source of error – to effect a “piece-wise rigid” registration of individual segmented structures. The msLevelCheck approach operates without such segmentation, operating instead directly on image intensities and gradients in an increasingly “local” registration through the multi-scale process to effect a global deformation of the vertebral labels. The algorithm was shown to accurately label vertebrae within a few mm of expert-defined reference labels, offering a potentially useful tool for safer spine surgery.
Read the full paper here.
M D Ketcha, T De Silva, A Uneri, M W Jacobson, J Goerres, G Kleinszig, S Vogt, J-P Wolinsky, and J H Siewerdsen, “Multi-stage 3D–2D registration for correction of anatomical deformation in image-guided spine surgery,” Phys Med Biol 62: 4604–4622 (2017).
Alisa Brown – a STAR at the I-STAR Lab

Alisa Brown was awarded a STAR (Summer Training and Research) Program scholarship for her research on the development of new rigid-body marker designs for surgical tracking and navigation. Alisa began research at the I-STAR Lab in 2016 using 3D printing to produce new marker tools for image-guided neurosurgery and orthopaedic surgery. Her research includes the development of a large, open-source library of marker designs to facilitate research in image-guided surgery, particularly for systems involving multiple tracked tools – for example, surgical pointers, endoscope, ultrasound probe, C-arm, and/or patient reference marker. Alisa is a rising senior in the Department of Biomedical Engineering at Johns Hopkins University.
Zbijewski Leads New Program for Imaging of Bone Health

No bones about it: Dr. Wojciech Zbijewski‘s research is breaking new ground in imaging technology and advancing the clinical understanding of conditions affecting the bones and joints. Dr. Z (“Wojtek”) and his team are developing new imaging methods that break conventional barriers to spatial resolution, give quantitative characterization of bone morphology, and shed new light on diseases such as osteoarthritis, rheumatoid arthritis, and osteoporosis. Underlying such advances are new methods for 3D imaging at spatial resolution beyond that of conventional computed tomography (CT).
Wojtek and colleagues are combining high-resolution CMOS detectors for cone-beam CT with advanced model-based 3D image reconstruction methods in an NIH R01 project that aims to resolve subtle changes in subchondral trabecular bone morphology as a sign of early-stage osteoarthritis (OA). Conventional methods detect OA only at later stages of cartilage degeneration and bone erosion, when treatment options are limited and often require joint replacement. Collaborators include Dr. Xu Cao (Orthopaedic Surgery) and Dr. Shadpour Demehri (Radiology).
Other NIH-funded research in collaboration with Dr. Carol Morris (Orthopaedic Surgery and Radiation Oncology) aims to quantify changes in bone quality following radiation therapy to identify early signs of fracture risk.
In collaboration with US Army Natick Soldier Research, Development, and Engineering Center (NSRDEC), Wojtek’s team is developing tools for quantitative image analysis of joint morphology in correlation with factors of injury risk (for example, ACL injury) – tools that have in turn driven new methods for automatic characterization of joint morphology for a variety of musculoskeletal (MSK) radiology applications.
In collaboration with Carestream Health, the team includes close collaboration with Dr. Shadpour Demehri (Hopkins Radiology), Dr. Greg Osgood (Hopkins Orthopaedic Surgery), and Dr. Lew Schon (Union Memorial Orthopaedic Surgery) to understand patterns of traumatic injury repair and fracture healing – pushing the limits of cone-beam CT spatial resolution and quantitative capability.
Dr. Zbijewski is faculty in the Department of Biomedical Engineering at Johns Hopkins University, with laboratories based at the Johns Hopkins Hospital – I-STAR Laboratory and Carnegie Center for Surgical Innovation.
Ultrasound + Cone-Beam CT Guidance: Paper by Eugenio Marinetto in CMIG
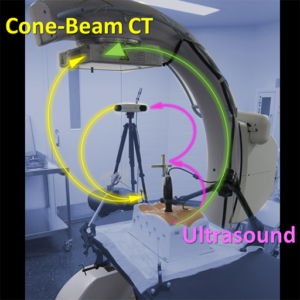
A paper published in the journal of Computerized Medical Imaging and Graphics (CMIG) reports the integration of C-arm cone-beam CT with a low-cost ultrasound imaging probe for needle interventions such as biopsy, tumor ablation, and pain management. The research reports a rigorous characterization of imaging performance for the ultrasound probe (Interson Vascular Access probe), including spatial resolution and contrast-to-noise ratio measured as a function of frequency and depth of field. The work also integrates the ultrasound probe via the PLUS Library for ultrasound-guided interventions, using a 3D-printed geometric calibration phantom and Polaris Vicra tracking system. The accuracy of image registration between ultrasound and cone-beam CT was ~2-3 mm at the needle tip, with anticipated improvement to be gained through enhancement of ultasound image quality. The work also demonstrates the potential for multi-modality (ultrasound-CBCT) deformable image registration using normalized mutual information (NMI), cross-correlation (NCC), or modality-insensitive neighborhood descriptors (MIND) similarity metrics. The research was supported by NIH, industry partnership with Siemens Healthcare, and a collaborative PhD student exchange program with the University Hospital Gregorio Marañón and University Carlos III de Madrid, first-authored by Dr. Eugenio Marinetto as part of his doctoral dissertation on advanced image-guided interventions.
Task-Driven CT: Paper by Grace Gang in Phys Med Biol.
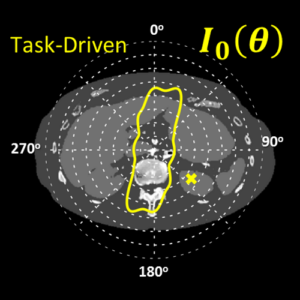
A paper published this month in the journal of Physics in Medicine and Biology reports a method that “takes imaging physics to task” to improve CT image quality and reduce dose. Grace Gang and coauthors Jeff Siewerdsen and Web Stayman combined methods for statistical 3D image reconstruction with mathematical models for task-based image quality to drive both the CT image acquisition and reconstruction process in a manner that is optimal to the imaging task. Among the findings is a new approach to tube current modulation that distributes x-ray fluence in a way that is completely different from conventional methods, maximizing imaging performance by reducing tube current in highly attenuating lateral views and instead spending radiation dose in less attenuating views where it has greater benefit to image quality. The result shows how model-based statistical 3D image reconstruction can completely change one’s approach to maximizing image quality. The work also shows how a joint optimization of acquisition technique and image reconstruction parameters is important in reducing radiation dose. The article can be found here and was supported by Dr. Stayman’s U01 grant on low-dose CT imaging.
Hao Dang Earns PhD in Biomedical Engineering

Hao Dang earned his Ph.D. from Johns Hopkins University after successfully defending his dissertation, entitled Model-Based Iterative Reconstruction in Cone-Beam Computed Tomography: Advanced Models of Imaging Physics and Prior Information. His thesis details the development of new model-based iterative reconstruction methods that leverage advanced models of imaging physics, task-based assessment of imaging performance, and patient-specific anatomical information from previously acquired images. The approaches uncovered in his work demonstrate substantial improvements in CBCT image quality for applications ranging from detection of acute intracranial hemorrhage to surveillance of lung nodules.
Hao Dang’s doctoral research was carried out in the I-STAR Lab) in Biomedical Engineering under supervision of Prof. Jeffrey H. Siewerdsen (primary advisor) and Prof. J. Webster Stayman (co-advisor). His Ph.D. dissertation focused on the development of new model-based iterative reconstruction methods to improve image quality – specifically, low-contrast, soft-tissue image quality – and reduce radiation dose in cone-beam computed tomography. His Ph.D. research culminated in multiple novel contributions to the field, leading to several published studies and conference presentations and subsequent translation of technology into clinical studies.
Hao’s Thesis Committee Members included Dr. Jeffrey H. Siewerdsen (Biomedical Engineering), Dr. J. Webster Stayman (Biomedical Engineering), Dr. Jerry L. Prince (Electrical and Computer Engineering) and Dr. Katsuyuki Taguchi (Radiology).
Congratulations, Hao!
Automatic Planning for Spine Surgery: Paper by Joseph Goerres
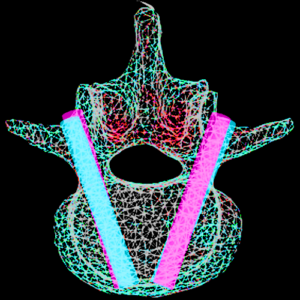
Dr. Joseph Goerres, postdoctoral fellow in the I-STAR Lab and Carnegie Center for Surgical Innovation, recently published a paper in Physics in Medicine and Biology that highlights the challenge of achieving precision guidance in spinal surgery.
His work addresses the challenging task of high-precision placement of instrumentation in spine surgery. Screw placement in particular is a challenging task due to the small bone corridors of the spinal pedicle in proximity to nerves and vessels. Spine surgeons benefit from precision guidance and navigation, as well as intraoperative quality assurance (QA) to ensure that each screw is placed safely. Implicit to both surgical guidance and QA is the definition of a surgical plan – i.e., definition of the desired screw trajectories and device selection for each vertebrae. Conventional approaches to surgical planning require time-consuming, manual annotation of preoperative CT or MRI by a skilled surgeon. Dr. Goerres’ paper demonstrates a method for automatically determining both the optimal trajectory and device (screw length and diameter). By leveraging a pre-defined atlas of vertebral shapes and trajectories in combination with deformable 3D registration to the patient’s preoperative image, the method demonstrated accurate, automatic plan definitions that agreed well with those defined by an expert spine surgeon.
Read the full paper here.
Michael Ketcha Wins Young Scientist Award at SPIE 2017

Michael Ketcha received the Young Scientist Award at the 2017 SPIE Medical Imaging Conference in Orlando FL for his paper entitled “Fundamental limits of image registration performance:effects of image noise and resolution in CT-guided interventions.” (Abstract Link)
Michael’s research tackles a largely unanswered, fundamental question in image science: How does the accuracy of image registration depend on image quality? His work yields a theoretical analysis that relates the lower bound in registration accuracy to the spatial resolution and noise in the underlying images, providing new insight on imaging techniques for image-guided interventions.
“While imaging performance is fairly well understood for detection and discrimination tasks,” says Michael, “comparatively little has been done to relate image quality factors to the task of image registration.” For CT and cone-beam CT-guided interventions, the methods derived in Michael’s work could lead to methods that involve much lower dose than conventionally used for image visualization but are still well suited to image registration. The work includes analysis of the robustness of various similarity metrics against image quality degradation and reveals a method for optimizing post-processing to minimize registration errors.
The Young Scientist Award recognizes outstanding work by early career researchers in the SPIE Medical Imaging conference on Image-Guided Procedures, Robotic Interventions, and Modeling. Michael Ketcha is a PhD student in Biomedical Engineering at Johns Hopkins University, advised by Dr. Jeff Siewerdsen in the I-STAR Lab and Carnegie Center for Surgical Innovation.
Ali Uneri Earns Ph.D. in Computer Science

Ali Uneri successfully defended his Ph.D. dissertation, entitled “Imaging and Registration for Surgical Guidance: Systems and Algorithms for Intraoperative C-Arm 2D and 3D Imaging” in December 2016. His work realized methods for mobile C-arm 2D and 3D imaging integrated with surgical navigation and advanced image registration methods. Among the breakthroughs in Ali’s work is the Known-Component Registration (KC-Reg) framework for extracting 3D information from 2D fluoroscopic views to give 3D guidance capability beyond that of conventional surgical tracking.
Dr. Üneri conducted his research advised by Dr. Jeff Siewerdsen in the I-STAR Lab, with work encompassing: (1) an extensible software platform for integrating navigational tools with cone-beam CT, including fast registration algorithms using parallel computation on general purpose GPU; (2) a 3D–2D registration approach that leverages knowledge of interventional devices for surgical guidance and quality assurance; and (3) a hybrid 3D deformable registration approach using image intensity and feature characteristics to resolve gross deformation in cone-beam CT guidance of thoracic surgery.
His PhD thesis examiners included Prof. Jeff Siewerdsen (Biomedical Engineering), Prof. Russ Taylor (Computer Science), Dr. Jerry Prince (Electrical and Computer Engineering), Dr. Jean-Paul Wolinsky (Neurosurgery), and Dr. Peter Kazanzides (Computer Science).
Congratulations, Ali!
Hao Dang Tackles Truncation Using Multi-Resolution CT Reconstruction
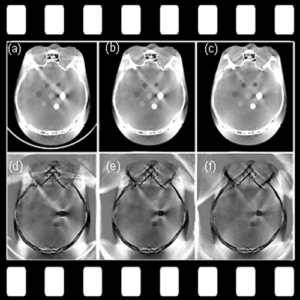
A recent paper published in Physics in Medicine and Biology by Hao Dang and coauthors in the I-STAR Lab reports a multi-resolution CT image reconstruction method that efficiently overcomes truncation effects, which are a particularly important problem in cone-beam CT (which often has limited field of view) and can confound iterative model-based image reconstruction (MBIR) methods.
Data truncation in CBCT results in artifacts that reduce image uniformity and challenge reliable diagnosis. For a recently developed prototype CBCT head scanner, truncation of the head and/or head holder can hinder the detection of intracranial hemorrhage (ICH).
The multi-resolution method is based on a similar approach shown by Qian Cao and coauthors for orthopaedic imaging, which allows simultaneous high-resolution reconstruction of bone regions and lower-resolution (lower-noise) reconstruction of surrounding soft tissue. In Hao Dang’s paper, a similar concept is used to overcome truncation artifacts by performing a high-resolution reconstruction of the interior with a lower-resolution reconstruction outside the RFOV.
The algorithm was tested in experiments involving CBCT of the head with truncation due to a carbon-fiber head support. Conventional (single-resolution) MBIR, showed severe artifacts and poor convergence properties, and the proposed method with a multi-resolution extension of the RFOV minimized truncation artifacts. Compared to brute-force reconstruction of the larger RFOV, the multi-resolution approach reduced computation time by as much as 95% (for an image volume up to 10003 voxels).
The findings provide a promising method for minimizing truncation artifacts in CBCT and may be useful for MBIR methods in general, which can be confounded by truncation effects.<>
Read the full paper in Phys Med Biol here.
Ja Reaungamornrat Earns PhD in Computer Science

Sureerat (Ja) Reaungamornrat successfully defended her PhD dissertation, entitled “Deformable Image Registration for Surgical Guidance Using Intraoperative Cone-Beam CT” in December 2016. Her work addresses new methods for deformable image registration in image-guided interventions, including: (1) a hybrid model for resolving large deformations of the tongue in multi-modality image-guided transoral robotic surgery; (2) a free-form registration method with rigid-body constraints on bones moving within an otherwise deformable soft-tissue context; and (3) a modality-insensitive neighborhood descriptor (MIND) method for registering preoperative MRI to intraoperative CT or cone-beam CT. Ja was supervised in both her Master’s and Doctoral work by Dr. Jeff Siewerdsen (Biomedical Engineering), and her PhD thesis examiners included Dr. Jerry Prince (Electrical and Computer Engineering), Dr. Russ Taylor (Computer Science), and Dr. A. Jay Khanna (Orthopaedic Surgery).
Congratulations, Ja!
Jennifer Xu Earns PhD in Biomedical Engineering

Jennifer Xu earned her Ph.D. in Biomedical Engineering from Johns Hopkins University. She successfully defended her thesis entitled “Image Quality, Modeling, and Design for High-Performance Cone-Beam CT of the Head” in Hurd Hall Auditorium on November 17, 2016.
Her dissertation shows that diagnosis and treatment of neurological and otolaryngological disease rely on accurate visualization of subtle anatomical structures in the head. Her work involved development of high-quality imaging of the head at the point of care to improve timeliness of patient monitoring and reduce risk associated with patient transport to and from the radiology suite. X-ray cone-beam computed tomography (CBCT) presents a promising technology for point-of-care head imaging with relatively low cost, mechanical simplicity, and high spatial resolution; however, CBCT systems are conventionally challenged in imaging of low-contrast structures (e.g., intracranial hemorrhage). Jennifer Xu’s PhD thesis detailed the design and development of CBCT imaging capability suitable to low-contrast lesion visualization. Her work encompasses physics-based modeling of image quality, system design and optimization, technical assessment of the resulting CBCT prototype CBCT, and translation to first clinical studies in the NCCU.
2016 Best New Radiology Device! Extremity Cone-Beam CT

The winner of the 2016 Best New Radiology Device from Aunt Minnie this year began as an industry collaboration betewen Johns Hopkins University and Carestream Health that eventually evolved into a commercial product. The system also won the 2016 Frost & Sullivan Award for New Product Innovation.
OnSight 3D is designed to bring advanced 3D imaging to orthopaedic surgeons, musculoskeletal radioloigsts, and rheumatologists. The system allows high-resolution imaging of the extremities, including weight-bearing lower extremities. It also features image processing algorithms for fast 3D image reconstruction, rendering, metal artifact reduction, and image analysis.
Tharindu DeSilva reports clinical utility of LevelCheck
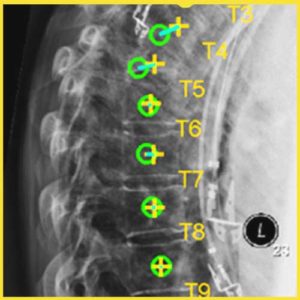
The “LevelCheck” algorithm for automatic radiographic labeling of the spine during surgery was evaluated by Tharindu De Silva and colleagues in a recent paper published in Spine. The clinical utility was assessed, and scenarios in which LevelCheck was most likely to be the beneficial were assessed in a retrospective study of 398 cases.
The results showed that LevelCheck was helpful in 42.2% of the cases (168/398), to improved confidence in 30.6% of the cases (122/398), and in no case diminished performance (0/398), supporting its potential as an independent check and assistant to decision support in spine surgery.
The scenarios for which LevelCheck was most likely to be beneficial included: cases with a lack of conspicuous anatomical landmarks; level counting across long spine segments; vertebrae obscured by other anatomy (e.g., shoulders); poor radiographic image quality; and anatomical variations/abnormalities.
The method demonstrated 100% geometric accuracy (i.e., correctly overlaid spine labels within the correct vertebral level in all cases) and did not introduce ambiguity in image interpretation. The study shows LevelCheck to be a potentially useful means of decision support in spine surgery target localization and motivates translation to prospective clinical studies.
This study was recently highlighted in the publication Spine Surgery Today. Read the full article here.
I-STARs at the 2017 SPIE Medical Imaging Conference

Eleven I-STARs will attend the 2017 SPIE Medical Image Conference in Orlando, FL from February 11-16, 2017 where they will present research in Image Registration, Cone-Beam CT, Image Reconstruction and Image-Guided Surgery.
A complete schedule of talks and posters –
Michael Brehler, Ph.D. – “Atlas-based automatic measurements of the morphology of the tibiofemoral joint” (12 February 2017 • 3:30 – 3:50 PM)
Grace J. Gang, Ph.D. – “Joint optimization of fluene field modulation and regularization in task-driven computed tomography” (13 February 2017 • 2:40 – 3:00 PM)
Graduate student Sarah Ouadah – “Task-driven orbit design and implementation on a robotic C-arm system for cone-beam CT” (14 February 2017 • 8:00 – 8:20 AM)
Alejandro Sisniega , Ph.D. – “Development and clinical translation of a cone-beam CT scanner for high-quality imaging of intracranial hemorrhage” (14 February 2017 • 9:00 – 9:20 AM)
Joseph Goerres, Ph.D. – “Deformable 3D-2D registration for guiding K-Wire placements in pelvic trauma surgery” (14 February 2017 • 11:10 – 11:30 AM)
Matthew W. Jacobson, Ph.D. – “Geometric calibration using line fiducials for cone-beam CT with general, non-circular source-detector trajectories” (14 February 2017 • 8:20 – 8:40 AM)
Graduate student Michael D. Ketcha – “Fundamental limits of image registration performance:effects of image noise and resolution in CT-guided interventions” (14 February 2017 • 10:30 – 10:50 AM)
Graduate student Qian Cao – “High-resolution cone-beam CT of the extremities with a CMOS detector: task-based optimization of scintillator thickness” (15 February 2017 • 8:20 – 8:40 AM)
Masters student Michael Mow – “Brain perfusion imaging using a reconstruction of difference approach for cone-beam computed tomography ” (15 February 2017 • 9:00 – 9:20 AM)
Aswin J. Mathews, Ph.D. – “Experimental evaluation of dual multiple aperture devices for fluence field modulated x-ray computed tomography” in a poster presentation on (15 February 2017 • 5:30 – 7:00 PM)
Tharindu de Silva Ph.D. – “C-arm positioning using virtual fluoroscopy for image-guided surgery” poster session on (15 February 2017 • 5:30 – 7:00 PM)
I-STARs at 102nd RSNA Meeting in Chicago

I-STARs present their research at the 102nd RSNA assembly and annual meeting in Chicago, Illinois.
Dr. Michael Brehler discussed “Quantitative Assessment of Trabecular Bone Microarchitecture Using High-Resolution Extremities Cone-Beam CT” on Sunday November 27th from 11:55-12:05pm.
Jeff Siewerdsen, PhD presented a talk entitled, Open Gantry Systems: Advances, Challenges, and New Applications on Sunday November 27th from 2:00-3:0 30pm.
Tharindu De Silva, PhD presented research on “Development and Clinical Translation of the “LevelCheck” Algorithm for Decision Support in Spine Surgery” at the Physics Tuesday Poster Discussion on Tuesday, Novmeber 29th from 12:15-12:45pm.
Dr. Jennifer Xu discussed “A Point-of-Care Cone-Beam CT System for Imaging of Intracranial Hemorrhage: Performance Characterization for Translation to Clinical Studies” on Wednesday, November 30th from 11:30-11:40am.
Matthew Jacobson, PhD presented his research on “Mobile C-Arm Cone-Beam CT: A New Prototype Incorporating Model-Based Image Reconstruction and Soft-Tissue Contrast Resolution” on Wednesday, November 30th from 11:40-11:50am.
Wojciech Zbijewski, PhD participated in an educational talk on Extremity CT, specifically MSK on Thursday, December 1st from 4:30-6:30pm.
Paper by Jen Xu: Image quality for a new cone-beam CT head scanner

A recent publication in Physics in Medicine and Biology entitled: “Evaluation of detector readout gain mode and bowtie filters for cone-beam CT imaging of the head”, reports evaluation of the efficacy and benefits of various detector gain modes and/or use of bowtie filters on the image quality (in terms of contrast and noise) in a Cone-Beam CT (CBCT) system, with application to high-quality imaging of low-contrast lesions in the head. The work develops a model of digitization noise as related to inherent additive electronics noise and panel gain mode, with applications to generalized analysis of the effects of gain mode and imaging dose on detective quantum efficiency analysis. Three bowtie filters of varying curvature and thickness were designed to evaluate tradeoffs in image quality from bowtie shape. The changes to dose distribution within the object imparted by bowtie filters was evaluated with a fast, GPU-based Monte Carlo simulation. The results from this evaluation were used in determination of the clinical protocols for a prototype CBCT scanner dedicated to imaging of acute intracranial hemorrhage.
This paper includes co-authors from Johns Hopkins Department of Biomedical Engineering (A. Sisniega, W. Zbijewski, H. Dang, JW. Stayman, JH. Siewerdsen), Department of Neuropathology (V. Koliatsos), Department of Neuroradiology (N. Aygun) and Carestream Health (DH. Foos, X. Wang).
J. Xu et al., Phys. Med. Biol. 61:5973 (2016)
Qian Cao Improving High-Resolution CT

Graduate student Qian Cao was chosen for the prestigious Howard Hughes Medical Institute International Student Research Fellowship, awarded to just 45 international predoctoral students studying in the United States. The award provides funding through the fifth year of PhD studies.
Qian’s research involves creating new technology for high-resolution CT scanning to detect minute bone changes that signal the early stages of osteoarthritis
“Osteoarthritis,” Cao explains, “is growing steadily more prevalent in the United States as the population ages.” Some estimates suggest that more than 67 million individuals will have osteoarthritis by 2030. “New research is showing that it can be detected in the early stages of progression, before damage to the joint and cartilage begin.”
Cao’s research is under way in the I-STAR Laboratory at Johns Hopkins, where he works under the mentorship of Dr. Wojciech Zbijewski and Dr. Jeffrey Siewerdsen in Biomedical Engineering at Hopkins. “Qian’s work is helping to break the conventional limits of spatial resolution in CT,” says Zbijewski.
(Link to full article) http://engineering.jhu.edu/magazine/2016/06/giving-ct-closer-look/#.V4ffwKI1yQ8
ISTARS Attend The 4th International Conference on Image Formation in X-Ray Computed Tomography
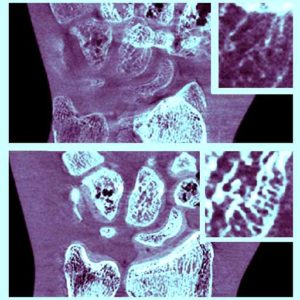
I-STARs will present new research in CT Imaging at the 4th International Conference on Image Formation in X Ray Computed Tomography between July 18th and July 22nd, 2016 at the Welcome Kongresshotel Bamberg, Germany.
Aswin Mathews, PhD presents research related to “Design of Dual Multiple Aperture Devices forDynamical Fluence Field Modulated CT” (General Session Tuesday July 19 9:00-9:20)
Alejandro Sisniega, PhD presents his research on “Motion Estimation Using a Penalized Image Sharpness Criterion for Resolution Recovery in Extremities Cone-Beam CT” (CBCT session, Thursday July 21, 15:40-16:00)
Grace Gang, PhD discusses “Task-Based Design of Fluence Field Modulation in CT for Model-Based Iterative Reconstruction” (Iterative Reconstruction Session, Thursday July 21, 11:20-11:40am)
PhD candidate, Steven Tilley shows research on “Modeling Shift-Variant X-Ray Focal Spot Blur for High-Resolution Flat-Panel Cone-Beam CT” (Thursday July 21, 13:20-15:00, Poster Session 3)
Hao Dang provides insight on “Task-Based Regularization Design for Detection of Intracranial Hemorrhage in Cone-Beam CT” (CBCT Session Thursday July 21 16:20-16:40)
I-STAR’s ‘Expanding Horizons’ at the AAPM 2016 Annual Meeting
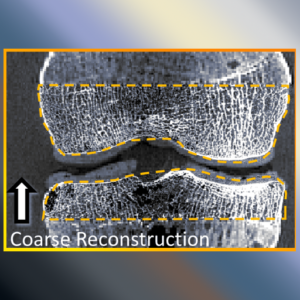
New research from the I-STAR lab will be presented at the AAPM Annual Meeting at the Walter E. Washington Convention Center in Washington DC betewen July 31st and August 4th, 2016.
Qian Cao will discuss his research on “High-Resolution Cone-Beam CT of the Extremities and Cancellous Bone Architecture with a CMOS Detector,” which earned a “Best in Physics” award. (Wednesday, August 3, 2016 at 7:30 – Room: 207A).
Jeff Siewerdsen, PhD discusses the “Advances in Image Registration and Reconstruction for Image-Guided Neurosurgery” (Monday, August 1, 2016 at 2:15pm – Room: 202).
Jennifer Xu presents her research on the “CBCT Head Scanner for Point-Of-Care Imaging of Intracranial Hemorrhage”. (Wednesday, August 3, 2016) at 7:50am -Room: 207A).
Ali Uneri will discuss “Operating Room Quality Assurance (ORQA) for Spine Surgery Using Known-Component 3D-2D Image Registration” (Wednesday, August 3, 2016 at 8:30am – Room: Ballroom A).
Sarah Ouadah presents the “Correction of Patient Motion in C-Arm Cone-Beam CT Using 3D-2D Registration”. (Wednesday, August 3, 2016 at 8:40am – Room: Ballroom A).
Tharindu De Silva, PhD will orate his research on “Registration of Preoperative MRI to Intraoperative Radiographs for Automatic Vertebral Target Localization” (Wednesday, August 3, 2016 at 8:50am – Room: Ballroom A).
Grace Gang, PhD will present her research on “Task-Driven Fluence Field Modulation Design for Model-Based Iterative Reconstruction in CT” (Thursday, August 4, 2016 at 10:20am – Room: 207B).
Masters Student, Xiaoxuan Zhang will present her research on “Image-Based Motion Estimation for Plaque Visualization in Coronary Computed Tomography Angiography” (Thursday, August 4 at 11:50am – Room 206)
Sureerat Reaugamornrat discusses the “Clinical Application of the MIND Demons Algorithm for Symmetric Diffeomorphic Deformable MR-To-CT Image Registration in Spinal Interventions” (Thursday, August 4, 2016 at 11:30am – Room: 206).
Finally, the 2016 Expanding Horizons session includes presentations by Michael Ketcha, Hao Dang, Ali Uneri, Sureerat Reaungamornrat and Dr. Alejandro Sisniega. (Tuesday, August 2, 2016) 9:30 AM – 11:00 AM Room: ePoster Theater). The session discusses cutting-edge topics from meetings outside the usual sphere of medical physics research, including KDD2016, ASNR, MICCAI, SIAM, the GPU Technology Conference.
Editor’s Pick! spektr 3.0 – New release of x-ray spectrum modeling software
The article entitled “SPEKTR 3.0 – A Computational Tool for X-Ray Spectrum Modeling and Analysis” was published in the August issue of Medical Physics, first-authored by Joshua Punnoose, a 3rd-year undergraduate in Biomedical Engineering at Johns Hopkins University. The technical note describes updates and improvements to the MATLAB toolkit for calculation of x-ray spectral characteristics using the improved TASMICS spectral model and a tuning function for users to calculate x-ray spectra matching output for a particular x-ray tube.
In light of this improved spectral model, this Technical Note reports an update to the spektr toolkit with TASMICS as the default method for spectral calculation. The code (referred to as spektr 3.0) also includes a new optimization tool to assist with a common issue faced by TASMIP/TASMICS/spektr users: how to model and match the exposure characteristics of a particular x-ray tube that differs from that in the underlying TASMICS simulation. The code was developed and validated using matlab release 2013b. The spektr 3.0/TASMICS implementation is detailed below, and the code is freely available for download at: http://istar.jhu.edu/downloads/. Video tutorials for the spektr function library, GUI, and optimization tool are available at the same link and at the following YouTube links:
1. https://www.youtube.com/watch?v=84DJndsj9CY,
2. https://www.youtube.com/watch?v=fXenb_LNMKM,
3. https://www.youtube.com/watch?v=Kn588r4arTM.
(Link to paper) http://scitation.aip.org/content/aapm/journal/medphys/43/8/10.1118/1.4955438
I-STARS at CARS: Imaging at the CARS 30th Annual Congress and Exhibition
Members of the I-STAR Lab head to Heidelberg for the Computed Assisted Radiology and Surgery Exhibition to present their research in IGS, Image Reconstruction and 3D Image Registration.
Wojtek Zbijewski, PhD, presents “Quantification of bone microarchitecture in ultra-high resolution extremities cone-beam CT with a CMOS detector and compensation of patient motion” (Thursday, June 23, 2016 Room 2 – 10:00am)
Jennifer Xu’s poster will present the latest work on “Cone-beam CT for point-of-care detection of acute intracranial hemorrhage.” (Friday June 24th, 8:00-11:15am)
Joseph Goerres, PhD, discusses “Atlas-based pedicle trajectory prediction for automatic assessment and guidance of screw insertions” (Surgical/Interventional Informatics, Friday June 24th Room 1 – 10:00am)
Tharindu De Silva, PhD, presents a method to assist spine surgeons in target localization in his talk entitled “LevelCheck” Localization of Spinal Vertebrae in Intraoperative Radiographs from Preoperative MRI” (Friday, June 24th Room 2 – 11:00am)
The Carnegie Center of Surgical Innovation: A different kind of operation

The Carnegie Center was highlighted in a recent BME newsletter.
For Jeff Siewerdsen, a professor of biomedical engineering, it was not hard to imagine such a synergistic connection between biomedical engineers and surgeons. “Clinical collaboration has always been the inspiration for our research,” he says. “What’s extraordinary is seeing that connection come to life in the same vintage operating rooms where so many landmark surgical procedures of the 20th century were pioneered.” The Carnegie Center for Surgical Innovation presents a unique resource for research, education, and translation that the departments of Neurosurgery and Biomedical Engineering hope will transform surgery, imaging science, and other disciplines in the 21st century.
“This is also a great example of the ‘one university’ concept championed by Johns Hopkins University President Ron Daniels,” says Siewerdsen, who collaborated with neurosurgery Professor Jean-Paul Wolinsky to create the center. “This space brings researchers from several departments to a focal point in the hospital with proximity to surgeons, identifying key clinical problems and working together to translate innovative solutions to clinical use.”
(link to full article – www. bme.jhu.edu/news-events)
PMB paper by Sarah Ouadah reports “self-calibration” of Zeego geometry for 3D imaging
A paper entitled; “Self-calibration of cone-beam CT geometry using 3D-2D image registration” by Sarah Ouadah, recently published in Physics in Medicine and Biology, presents a method for geometric calibration of an arbitrary source-detector C-arm orbit by registering 2D projection data to a previously acquired 3D image. This paper includes co-authors from Johns Hopkins Biomedical Engineering Department (JW Stayman, Grace Gang and Jeff Siewerdsen) and Siemens collaborator (Tina Ehtiati).
The algorithm uses information from the image gradients and a statistical optimizer to determine the transformation that provides in the best registration. The resulting transformation provides a “self-calibration” of system geometry. Using this algorithm, visible improvement was evident in CBCT reconstructions, particularly about high-contrast, high-frequency objects (e.g., temporal bone air cells and a surgical needle).
I-STAR Seminar: Dr. Ke Li on the Theoretical Applications of Four Dimensional Cascaded Systems Analysis of Cerebral CT Perfusion Imaging
The I-STAR lab welcomes Dr. Ke Li for his seminar on Thursday, May 26th, entitled: Four-dimensional cascaded systems analysis of cerebral CT perfusion imaging: Theoretical framework and potential applications.
The recent success of clinical trials on endovascular stroke therapy has brought cerebral CT perfusion (CTP) imaging in the spotlight. CTP is used by many clinical centers for the diagnosis and prognosis of strokes, patient selection for endovascular therapy, and post-treatment evaluation. However, the exact role of CTP in endovascular therapy is somehow controversial, primarily due to the relatively large uncertainties in quantifying perfusion deficits from noisy CTP maps. This talk will present an imaging science framework that describes the signal and noise propagation process through each subcomponent of the CTP systems. The framework includes both deconvolution- and nondeconvolution-based postprocessing methods, and it covers different types of perfusion parameters such as cerebral blood flow and time-to-max. This framework has been used to identify the culprits for the poor imaging performance of the current CTP technology, and it has provided the needed scientific guidance for the development and optimization of several new CTP technologies, which potentially enables reliable quantification of perfusion deficits with reduced radiation dose.
Ke Li is a clinical health science (CHS)-track Assistant Professor of Medical Physics and Radiology, School of Medicine and Public Health, University of Wisconsin-Madison. He received his MS degree in Physics from the Ohio State University in 2009 and PhD in Medical Physics from UW-Madison in 2013. His major research interests include x-ray phase contrast breast imaging, cerebral CT perfusion imaging, and low dose body CT imaging. He has served as an ad hoc member of an NIH study section, guest associate
editor of Medical Physics, reviewer for PNAS, Scientific Reports, and other 8 journals. He is the recipient of the 2015 AAPM Research Seed Funding Initiative Award for a project entitled “High Quality and Sub-mSv Cerebral CT Perfusion Imaging.”
The seminar will be held on Thursday, May 26th at 1:00 pm in the Talbot Library (Traylor 709) on the School of Medicine campus.
Dr. Siewerdsen inducted in the AIMBE College of Fellows

Jeff Siewerdsen, Principal Investigator for the I-STAR Lab, Director of The Carnegie Center for Surgical Innovation, and Professor of BME at Hopkins, was recently inducted into the AIMBE College of Fellows for his contributions to biomedical imaging and image-guided interventions. The induction ceremony was held at the National Academy of Sciences in Washington DC on April 4, 2016. Induction in the College is based on nomination and peer review representing the top 1-2% of the engineering community. The Fellows are instrumental in realizing the AIMBE vision for innovation and benefit to healthcare.
Congratulations, Dr. Siewerdsen, on this achievement!
I-STAR Seminar: Dr. Paul Kinahan on Quantitative Molecular Imaging with PET/CT

The I-STAR lab welcomes Dr. Paul Kinahan for his seminar on Monday, March 21, entitled:
Quantitative Molecular Imaging with PET/CT: Why Does it Matter and How Do We Do It?
PET or PET/CT imaging has become a standard component of diagnosis and staging in oncology and is also used for specific neurological and cardiovascular tasks. Because of its high sensitivity, quantitative nature, and its ability to image deep into large objects, it is arguably the most powerful technology for in vivo molecular imaging in humans. Dr. Kinahan’s seminar will review the barriers, both technological and otherwise, to improved quantitative PET imaging and describe recent efforts and accomplishments in removing or avoiding these barriers.
Dr Kinahan is Professor and Vice-Chair of Research in Radiology, and Adjunct Professor of Bio-engineering and Physics. at the University of Washington. He is also the Director of UWMC PET/CT Imaging Physics and Head of the UW Imaging Research Laboratory. His research includes the physics of PET/CT imaging, the use of statistical image reconstruction, optimization of PET/CT image quality, and the use of quantitative analysis in oncology imaging.
The seminar will be held on Monday, March 21st, 2016 from 3-4 pm in the Talbot Library (Traylor 709) on the School of Medicine campus. The seminar will be video telecast to Clark 110 on the Homewood Campus.
Congratulations! Dr. Jean-Paul Wolinsky, Professor of Neurosurgery

Congratulations!!! to Dr. Jean-Paul Wolinsky, MD, promoted to Professor of Neurosurgery at Johns Hopkins University. Dr. Wolinsky’s work focuses on the development of minimally invasive surgical techniques for the resection and stabilization of neoplastic disease of the spine and novel surgical strategies for pathology of the occipital-cervical junction and complex spinal reconstruction. He is a pioneer of anterior approaches to the cervical spine and is a close collaborator with the I-STAR Lab on topics of intraoperative imaging and patient safety. Dr. Wolinsky is also Co-Director of the Carnegie Center for Surgical Innovation.
Congratulations, Professor Wolinsky on this well-deserved achievement!
I-STAR Sureerat “Ja” Reaungamornrat shines on the 2016 SPIE award podium!

Sureerat Reaungamornrat, better known as “Ja”, is the recipient of two awards at the 2016 SPIE Medical Conference. She earned the SPIE 2016 Medical Imaging Young Scientist award and the Robert Wagner All-Conference Best Student Paper award. Her submission, entitled: “MIND Demons for MR-to-CT Deformable Image Registration in Image-Guided Spine Surgery” stood out among a group of competitive papers and earned her this great achievement. This is not Ja’s first time at the podium at SPIE – she previously won the Young Scientist award in 2014 and the Best Student Paper Award in 2013 and 2014.
The subject of Ja’s research “MIND Demons”, has nothing to do with your mind and nothing to do with demons. She explains that “It is a 3D image registration method that uses the MIND metric to compare the similarity between two images and the Demons algorithm to drive the deformable alignment.” The research offers particular promise for application in image-guided surgery, where surgical planning and visualization of the target is often performed in preoperative MRI and high-precision surgical guidance is performed using intraoperative CT. The method allows the MRI and planning information to be deformably registered into the up-to-date intraoperative CT. Under the hood, MIND Demons yields registration results that are symmetric / diffeomorphic, is insensitive to the inherent lack of correspondence between MRI and CT image intensities, and uses a Gauss-Newton optimization for fast convergence.” Ja’s paper reports the details of the MIND Demons algorithm, tests its performance in simulation, phantom studies, and clinical data, and demonstrates superior registration accuracy to other registration techniques. Translation of the method to clinical use could facilitate safer surgery with increased precision and confidence in targeting.
>Congratulations, Ja!
Introducing the Carnegie Center for Surgical Innovation!

The Carnegie Center for Surgical Innovation is a new, nationally unique resource for research, education, and translation in imaging and image-guided interventions. Located in the heart of Johns Hopkins Hospital and formed in collaboration between the Department of Biomedical Engineering and Department of Neurosurgery, the Center provides a synergistic co-location of expertise to identify major clinical needs, drive research and development of new technologies, translate advances to clinical use, and cultivate the next generation of engineers and clinicians. Pillars of the Carnegie mission are Research, Education, and Translation, with a focus on applications of novel imaging systems in neurosurgery, orthopaedic surgery, and otolaryngology – head and neck surgery for improved surgical precision and patient safety.
The Carnegie Mission focuses on the following:
Research – advances in surgical techniques employing intraoperative imaging and computer assistance for improved surgical precision and quality.
Education – undergraduate and graduate education in engineering as well as training of medical residents and fellows.
Translation – accelerating the translation of research to first clinical studies and the transfer of innovations to broader commercial availability.
The Carnegie Center is directed by Jeffrey Siewerdsen (Professor of Biomedical Engineering and head of the I-STAR Lab) and by Jean-Paul Wolinsky (Professor of Neurosurgery). Resources at the Carnegie Center include laboratories for biomedical imaging, high-speed computing, machining and 3D printing, and outside-the-OR training facilities. Located in the heart of the the Carnegie ORs established in 1935 at Johns Hopkins Hospital, the Carnegie Center offers a new home for collaboration among engineers and clinicians.
http://www.hopkinsmedicine.org/news/articles/back-to-the-future
I-STARS Converge at SPIE Medical Imaging 2016

I-STARs converge at the 2016 SPIE Conference in San Diego, California to present talks on topics ranging from 3D image reconstruction to image registration and image-guided surgery.
Michael Ketcha will discuss “Automatic Masking for Robust 3D-2D Image Registration in Image-Guided Spine Surgery” (Session 2: Sunday 28 February – 10:10AM-12:10PM)
Sureerat Reaungamornrat presents her research on “MIND Demons for MR-to-CT Deformable Image Registration in Image Guided Spine Surgery” (Session 3: Sunday 28 February – 1:20PM-3:00PM)
Alejandro Sisniega, PhD, presents “Image-based motion compensation for high-resolution extremities cone-beam CT” (Session 4: Sunday 28 February – 3:30PM-5:30PM)
Jeffrey Siewerdsen, PhD will participate in a workshop entitled Interventional Procedures: Emerging Technologies and Clinical Applications. He will discuss breakthroughs in “Interventional Imaging Technologies for Therapy Guidance”. (Workshop: Sunday 28 February – 5:45-7:45pm)
Jennifer Xu presents on “Design and Characterization of a Dedicated Cone-Beam CT Scanner for Detection of Acute Intracranial Hemorrhage” (Session 6: Monday 29 Feb – 10:10AM-12:10 PM)
Steven Tilley presents on “Nonlinear Statistical Reconstruction for Flat-Panel Cone-Beam CT with Blur and Correlated Noise Models” (Session 6: Monday 29 Feb – 10:10AM-12:10 PM)
J. Web Stayman, PhD, presents a talk on “Fluence-Field Modulated X-ray CT using Multiple Aperture Devices” (Session 7: Monday 29 February – 1:20PM-3:40PM)
Hao Dang presents “Regularization Design for High-Quality Cone-Beam CT of Intracranial Hemorrhage Using Statistical Reconstruction” (Session PS2: Monday 29 February 5:30PM-7:00PM)
And finally, Grace Gang, Phd, presents on the topic of “Task-driven tube current modulation and regularization design in computed tomography with penalized-likelihood reconstruction” (Session 15: Wednesday 2 March – 3:30PM-5:30PM)
I-STARs at 101st RSNA Conference in Chicago
At the 101st meeting of the RSNA, four presentations from the I-STAR Lab highlight new research in CT imaging physics. Topics range from the development of a new cone-beam CT system for detection of traumatic brain injury to dual-energy CT for detection of bone marrow edema.
Jennifer Xu, a PhD student in Biomedical Engineering at Johns Hopkins University, presents on “Development of a Dedicated Cone-beam CT System for Imaging of Intracranial Hemorrhage.” Her work uses a task-based image quality model to design a new cone-beam CT system for reliable detection of brain injury at the point of care. By combining optimal system design with high-quality artifacts correction and model-based 3D image reconstruction, the research has enabled development of a scanner prototype for first clinical tests in the ICU.
J. Web Stayman, PhD, Assistant Professor of Biomedical Engineering at Johns Hopkins University presents 2 talks on advanced 3D imaging methods – the first involving “Fluence field modulation for low-dose x-ray computed tomography using compact multiple aperture devices,” and the second on “Polyenergetic known component reconstruction (KCR) for flat-panel CBCT with unknown material compositions and unknown x-ray spectra.”
Finally Wojciech Zbijewski, PhD, Faculty in Biomedical Engineering at Johns Hopkins University, will present on “Ultra-High Resolution Quantitative Cone Beam CT of the Extremities with a CMOS X-ray Detector.” His work advances a cone-beam CT system for extremities imaging beyond conventional spatial resolution limits to permit quantitative analysis of subchondral bone morphology. Through development of a new imaging chain with a high-resolution detector, model-based multi-resolution 3D image reconstruction, and motion correction methods, the research promises a new means for in vivo quantitative image-based biomarkers of bone health and disease progression in osteoarthritis.
Hao Dang Named a 2016 Siebel Scholar

Hao Dang, a graduate student in the I-STAR Lab at Hopkins, was recently named to the 2016 class of Siebel Scholars for outstanding research, academic achievements, and leadership. The Siebel Scholars program was established by the Thomas and Stacey Siebel Foundation in 2000 to recognize talented students at the world’s leading graduate schools of business, computer science, bioengineering, and energy science. The Engineering program at Hopkins is proud to be among the few programs in the world recognized by the Siebel Scholars Foundation. Hao is a PhD student in Biomedical Engineering supervised by Professor Jeffrey H. Siewerdsen. His thesis focuses on the development of new methods for 3D image reconstruction in cone-beam CT (CBCT) using advanced models of imaging physics. His project involves development of an imaging system for improved detection of intracranial hemorrhage. Hao’s work has yielded substantial improvement in image quality compared to traditional reconstruction methods by accurately incorporating the image noise characteristics associated with artifact correction (paper). His previous work includes automatic image-to-world registration for surgical guidance using C-arm CBCT system (paper) and work with Dr. J. Webster Stayman on novel image reconstruction using prior image information for dose reduction and image quality improvement (paper). The Siebel Scholarship includes a stipend support from the Siebel Scholars Foundation for his final year of graduate studies.
Best Paper in Medical Physics Awarded to Jennifer Xu

Jennifer Xu and coauthors were awarded this year’s Sylvia and Moses Greenfield Award for the Best Paper in Medical Physics. Her paper, entitled “Cascaded systems analysis of photon counting detectors,” reports an analytical model for the imaging performance of x-ray photon counting detectors. The research extends analytical models that have been important to the development and application of (energy-integrating) flat-panel detectors to account for important characteristics of photon counters, such as the pulse height threshold and possible charge sharing effects. The work also quantifies the conditions for which photon counting detectors are expected to provide greatest benefit to imaging performance in comparison to conventional flat-panel detectors. The research was supported by that National Institutes of Health and supervised by Dr. Jeff Siewerdsen in collaboration with scientists at Philips Healthcare. Coauthors are W. Zbijewski, G. Gang, J. W. Stayman, K. Taguchi, M. Lundqvist, E. Fredenberg, J. A. Carrino, and J. H. Siewerdsen. Congratulations to Jen and coauthors on this outstanding achievement!
Four I-STAR Talks in CARS Barcelona
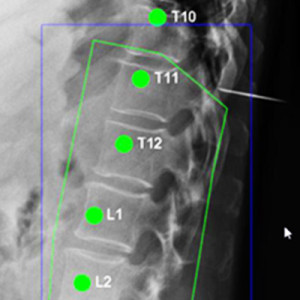
The I-STARs head to Barcelona for the 29th Annual CARS Meeting on Computer-Assisted Radiology and Surgery. The program includes four talks from the I-STAR Lab on topics ranging from imaging of TBI to systems for safer surgery, including new technical breakthroughs in cone-beam CT and ultrasound imaging.
Alejandro Sisniega, Postdoctoral Fellow in Biomedical Engineering at Hopkins, returns to his home country to present the development of a cone-beam CT system dedicated to high-quality imaging of traumatic brain injury (TBI) and intracranial hemorrhage (ICH). The system was designed from first principles of task-based image quality to provide performance optimal to ICH detection and combines cutting-edge systems for high-fidelity artifacts correction and model-based image reconstruction. (program)
Wojciech Zbijewski, Faculty Research Associate in Biomedical Engineering at Hopkins, presents new work in high-resolution orthopaedics imaging, extending a previously reported system for extremities cone-beam CT to include advanced model-based image reconstruction and a new scanner design in development to allow quantitative assessment of trabecular micro-architecture. Such work opens new possibilities for image-based biomarkers of early osteoarthritis by detecting subtle morphological precursors to cartilage and joint degeneration. (program)
Eugenio Marinetto, PhD Student at Universidad Carlos III and Johns Hopkins University, reports the integration of C-arm cone-beam CT and ultrasound imaging for surgical guidance. Eugenio’s work includes the characterization of imaging performance of a low-cost ultrasound probe, its integration with the TREK surgical guidance system, and registration with mobile C-arm cone-beam CT. (program)
Finally, Tharindu De Silva, Postdoctoral Fellow in Biomedical Engineering at Hopkins, reports on the development and clinical application of a 3D-2D registration method for guidance and decision support in spine surgery. Translating the LevelCheck algorithm to a large clinical study underway at Johns Hopkins Hospital, Tharindu shows how novel similarity metrics improve the robustness of the registration process and support automatic spine localization in a manner that works within existing surgical workflow. Compared to conventional manual “level counting,” the LevelCheck algorithm allows automatic labeling of vertebral levels in intraoperative radiographs as an independent check on target localization that could reduce errors, improve speed, and reduce stress in the OR. (program)
I-STARs Shine at AAPM 2015, Anaheim CA

Five talks from the I-STAR Lab highlight advances in 3D imaging and image-guided interventions at the 57th Annual Meeting of the AAPM, Anaheim CA.
Jennifer Xu presents on the design and optimization of a cone-beam CT head scanner for detection of acute intracranial hemorrhage. Using task-based detectability index as an objective function for system optimization, Jen’s work extends a cascaded systems model for 3D imaging performance to design the system geometry, x-ray source and detector configuration, and image acquisition technique optimal for the detection of low-contrast lesions. (abstract)
Alejandro Sisniega extends previous work on Monte Carlo modeling to yield a fast (GPU-based) system for dose calculation for cone-beam CT of the head. His work sheds new light on the asymmetric dose distributions associated with short-scan cone-beam imaging, include methods to spare dose to the anterior (eye lens) and the benefits arising from incorporation of a bowtie filter. (abstract)
Grace Gang presents on the topic of “Task-Driven Imaging for Cone-Beam CT in Interventional Guidance.” Her work extends analytical models for the local MTF, NPS, and detectability index in 3D images reconstructed by penalized likelihood estimation to obtain C-arm orbital trajectories that maximize image quality with respect to a specified task. Such work represents an exciting departure from conventional imaging methods, instead leveraging knowledge of the imaging task to maximize image quality and reduce dose. Grace’s work draws from an AAPM Research Seed Funding Grant and earned recognition as a Featured Presentation at the conference. (abstract)
Wojciech Zbijewski joins John Boone, Guang-Hong Chen, and Rebecca Fahrig in a symposium highlighting advances in cone-beam CT. Wojciech’s work focuses on cone-beam CT for musculoskeletal / orthopaedics imaging, including new cone-beam CT scanning systems offering spatial resolution beyond conventional limits. Such work opens the possibility for in vivo quantitative assessment of trabecular micro-architecture, which is recognized as an important image-based biomarker for early osteoarthritis. He also reports the development of dual-energy CBCT for visualization of bone marrow edema, which is usually occult in CT (and conventionally the domain of MRI) but can be rendered conspicuous through dual-energy decomposition of marrow and edemous fluid using advanced model-based reconstruction methods. (abstract)
Finally, Tharindu De Silva presents on the topic of 3D-2D image registration for image-guided spine surgery, showing how the robustness of vertebrae localization can be dramatically improved through incorporation of novel similarity metrics within the registration framework. Tharindu’s work also extends the LevelCheck algorithm for spine localization to a large clinical study underway at Johns Hopkins University and demonstrates valuable decision support without disruption of clinical workflow. (abstract)
Four Presentations at Fully 3D 2015
New methods for model-based 3D image reconstruction are the focus of The Fully 3D Meeting, May 31 – June 4, in Newport Rhode Island, including 4 presentations from the I-STAR Lab:
Web Stayman leads the charge (Monday, June 1) with breakthrough work on “Task-Based Optimization of Source-Detector Orbits in Interventional Cone-beam CT.” By incorporating a model for task-based imaging performance as the objective function, Web shows how the x-ray source and detector orbit in cone-beam CT acquisition can be optimized to maximize image quality. Such work suggests a new paradigm for CT imaging in which data is collected based upon prior knowledge of the patient and a model for the imaging task.
Steven Tilley, PhD Student in Biomedical Engineering at Hopkins, presents his talk entitled “Generalized Penalized Weighted Least-Squares Reconstruction for Deblurred Flat-Panel CBCT” on Monday, June 1. By incorporating models for system blur arising from the x-ray focal spot size and detector scintillator, Steve shows a method for model-based reconstruction that achieves superior noise and spatial resolution in comparison to conventional deconvolution methods and identifies cone-beam CT configurations for which such modeling is important to maximizing image quality.
Amir Pourmorteza, Postdoctoral Fellow in Biomedical Engineering at Hopkins, presents on the topic of “Reconstruction of Difference using Prior Images and a Penalized-Likelihood Framework” on Tuesday, June 2. Amir’s work shows a model-based reconstruction method capable of delineating subtle changes in patient morphology based on sparse, low-dose data. Such work could be especially valuable in longitudinal imaging studies in which detection of change – e.g., tumor growth or shrinkage – is important.
Qian Cao, PhD Student in Biomedical Engineering at Hopkins, presents a poster entitled, “Multi-Resolution Penalized Weighted Least-Squares Reconstruction for Quantitative Cone-Beam CT Imaging of Bone Morphology” on Wednesday, June 3. Qian’s work builds from a new program in high-resolution orthopaedics imaging headed by Dr. Wojciech Zbijewski, showing a model-based reconstruction method in which various regions of an image can be reconstructed with disparate image quality characteristics – e.g., ultra-high-resolution within regions of bone for visualization of trabecular structure, simultaneous with lower-resolution, low-noise reconstruction in regions of soft tissue.
I-STAR Talks at SPIE Medical Imaging 2015
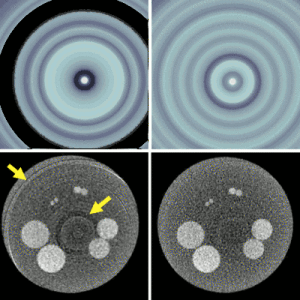
Six presentations from the I-STAR Lab report advances in imaging physics, 3D image reconstruction, image registration, and image-guided interventions: SPIE Medical Imaging 2015 (program)
— Dang et al., Cone-Beam CT of Traumatic Brain Injury Using Statistical Reconstruction with a Post-Artifact-Correction Noise Model (Sunday, February 22 — 10:30am, Room: Crystal C – Session 2)
— Zbijewski et al., Dual-Energy Imaging of Bone Marrow Edema on a Dedicated Multi-Source Cone-Beam CT System for the Extremities (Monday, February 23 — 10:50am, Room: Crystal C – Session 6)
— Sisniega et al., Spectral CT of the Extremities with a Silicon Strip Photon Counting Detector (Monday, February 23 — 1:20pm, Room: Crystal C – Session 7)
— Ouadah et al., Self-Calibration of Cone-Beam CT Geometry Using 3D-2D Image Registration: Development and Application to Tasked-Based Imaging with a Robotic C-Arm (Tuesday, February 24 –11:30am, Room: Oceans 4 – Session 9)
— Uneri et al., Known-Component 3D-2D Registration for Image Guidance and Quality Assurance in Spine Surgery Pedicle Screw Placement (Tuesday, February 24 — 2:20pm, Room: Oceans 4 – Session 10)
— Gang et al., Task-Driven Imaging in Cone-Beam Computed Tomography (Wednesday, February 25 — 1:20pm, Room: Crystal C – Session 14)
RSNA 2014: Imaging from Head to Toe
Four RSNA talks from the I-STAR Lab at Johns Hopkins University include cone-beam CT research in a spectrum of emerging applications – from “head to toe.” For imaging of traumatic brain injury (TBI), Alejandro Sisniega presents a comprehensive framework for artifact correction, including high-speed Monte Carlo correction of x-ray scatter as well as beam-hardening, image lag, and low-frequency glare effects. The framework yields cone-beam CT images with quality suitable to detection of small brain hemorrhages. For a variety of image-guided interventions using intraoperative C-arms for cone-beam CT, Grace Gang presents a method for acquiring images with optimal image quality driven by a specification of the imaging task. Using a prospective definition of the region and spatial frequencies of interest, her work shows how task-driven imaging yields protocols for mA modulation, kernel modulation, and non-circular orbits that are distinct from conventional paradigms and produces images with higher task performance. For extremities imaging, Wojciech Zbijewski is extending the capabilities of CBCT of the extremities to include dual-energy imaging and tackling the specific challenge of detecting bone marrow edema (BME). Using a dedicated extremity scanner developed in previous work for high-resolution imaging and combining with statistical reconstruction methods combined with dual-energy decomposition, his work begins to show the promise of detecting subchondral edema as in rheumatoid and osteo-arthritis. Finally, Gaurav Thawait presents the latest findings from a clinical study of CBCT imaging of the ankle and foot, showing the ability of high-resolution CBCT to provide accurate measurement and visualization of trauma and fracture healing.
Three of the talks (SSA19-03 Sisniega et al., SSA19-06 Thawait et al, and SSA19-09 Gang et al.) are included in the Physics session entitled “Computed Tomography I: New Techniques / Systems” following Dr. Willi Kalender’s Keynote Address. The fourth (SSC12-09 Zbijewski et al.) is in the Physics session entitled “Computed Tomography II: Dual-Energy / Spectral CT.”
Med Phys Paper on Image Quality of Photon Counting Detectors Earns Editor’s Pick
A new paper by Jennifer Xu et al. earned Editor’s Pick in the Medical Physics journal, reporting a model for imaging performance in photon counting detectors based on cascaded systems analysis. The paper includes coauthors (W. Zbijewski, G. Gang, J. W. Stayman, K. Taguchi, J. A. Carrino, and J. H. Siewerdsen) from Biomedical Engineering and Radiology at Johns Hopkins University as well as collaborators at Philips Healthcare (M. Lundqvist and E. Fredenberg). By extending a cascaded systems model of spatial-frequency-dependent MTF, NPS, and DQE to the propagation of signal and noise in a photon counting detector, the paper provides a theoretical framework for understanding the advantages, limitations, and factors governing imaging performance of this important, emerging detector technology. The model demonstrated agreement with the measured signal and noise characteristics of a silicon strip photon counter on an experimental system for photon counting spectral CT and quantified imaging performance over a broad range of operating conditions. For example, the results identify the conditions for which photon counters give a performance advantage over flat-panel detectors and demonstrate the challenges presented by charge sharing, electronic noise, and threshold selection in optimizing performance. The model provides a basis that can be extended to task-based assessment of imaging performance (e.g., system design and optimization based on model observer detectability index) for application of photon counting detectors in projection imaging, tomosynthesis, CT, and spectral imaging. (link)
Task-Based Image Quality Model for Model-Based Image Reconstruction
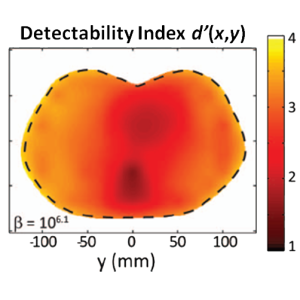
3D model-based image reconstruction offers advantages of improved image quality and reduced dose, but nonlinear characteristics of the reconstruction process challenge conventional image quality models. A paper by Grace Gang, Web Stayman, Wojciech Zbijewski, and Jeff Siewerdsen published in Medical Physics (Volume 41(8) 2014) extends task-based image quality modeling to such reconstruction methods. Previous work by Jeff Fessler and colleagues at the University of Michigan established a basis for modeling the PSF and COV for images reconstructed by penalized likelihood estimation with a quadratic penalty. The paper by Gang et al. combines that work with cascaded systems models of the local MTF and local NPS and extends to task-based modeling of the detectability index in a manner that accounts for non-stationarity in spatial resolution and noise. The model was validated in comparison to measurements with a variety of simple and anthropomorphic phantoms, providing an important new theoretical foundation for understanding the factors governing image quality in model-based 3D image reconstruction. (http://www.ncbi.nlm.nih.gov/pubmed/25086533)
Research Awards at AAPM 2014 (Austin TX)

Grace Gang and Adam Wang – both postdoctoral fellows in the I-STAR Lab at Hopkins – won awards for outstanding research at the annual meeting of the AAPM in Austin TX, July 24, 2014. Grace was awarded an AAPM Research Seed Funding Grant for her project entitled “Task-Driven, Patient-Specific Imaging for CT and Cone-Beam CT,” work that combines the fundamental physical models of image quality with statistical reconstruction to improve imaging performance and reduce dose. Adam Wang was awarded the Junior Investigator Award for his abstract entitled, “Low-Dose C-arm Cone-Beam CT with Model-Based Image Reconstruction for High-Quality Guidance of Neurosurgical Intervention.” Adam’s work demonstrates the powerful role that advanced 3D imaging methods hold for image-guided procedures, providing high-quality images in the OR for guidance, quality assurance, and improved patient safety.
Six Talks at AAPM 2014 – The Latest in Imaging Physics
The I-STAR Lab presented 6 talks at the annual meeting of the American Association of Physicists in Medicine (AAPM) in Austin TX, July 20 – 25, 2014, featuring the latest in imaging physics, analysis, reconstruction, and Monte Carlo simulation.
— Wojciech Zbijewski presented an overview and update in an educational symposium on Monte Carlo simulation, including variance reduction and kernel smoothing acceleration methods. His work shows such methods to provide accurate MC simulation on timescales consistent with real applications in diagnostic imaging and image-guided procedures.
— Alejandro Sisniega presented a framework for high-quality cone-beam CT of traumatic brain injury (TBI) including high-fidelity artifact correction. Using GPU-accelerated Monte Carlo scatter correction combined with parametric models of beam-hardening, lag, and veiling glare, his work demonstrates major improvement in CBCT image quality consistent with the challenging tasks of TBI imaging.
— Qian Cao presented a model for 3D image analysis in cone-beam CT of the joints. Using an electrostatic model that envisions the joint as a capacitor, his work overcomes conventional limitations of simple joint space measures and demonstrated significant improvement in the ability to detect osteoarthritis associated with subtle changes in joint space morphology.
— Adam Wang presented a new method for high-speed statistical image reconstruction using accelerated convergence methods based on Nesterov’s method. Without loss in image quality, Adam’s work shows that methods conventionally requiring an hour or more to reconstruct can be performed in 2 minutes, bringing advanced iterative reconstruction methods to a practical timescale for image-guided surgery.
— Web Stayman presented the latest advances in 3D image reconstruction in an invited symposium, including how specification of the imaging task can be rigorously incorporated in the image acquisition and reconstruction process. His work shows how advanced imaging platforms such as a robotic C-arm can be used to carry out noncircular orbits that are optimal in image quality and dose for image-guided procedures.
— Jeff Siewerdsen presented a plenary in the President’s Symposium entitled “Innovation in the Medical Physics Enterprise.” He addressed the central role that medical physicists play in advancing the state of care through identification of pertinent clinical needs, development of innovative solutions, and translation to clinical care. Particularly in a changing, cost-sensitive landscape, the role of medical physicists in multi-disciplinary research research and innovation is greater than ever.
Four Presentations from The I-STAR Lab at the 2014 International CT Meeting, Salt Lake City
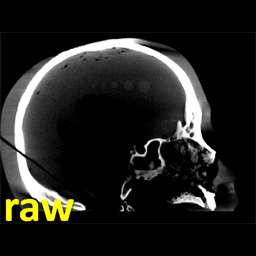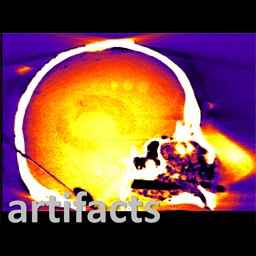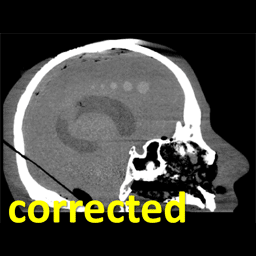
The latest research in advanced CT image reconstruction methods, modeling, and image quality are presented in four presentations from The I-STAR Lab at the 2014 International CT Meeting in Salt Lake City (June 23 – 26). Highlights include:
— W. Zbijewski et al., “A Sparse Monte Carlo Method for High-Speed, High-Accuracy Scatter Correction for Soft-Tissue Imaging in Cone-Beam CT.” As illustrated in the animation at left, cone-beam CT can suffer from image artifacts that pose a major challenge to soft tissue visibility and diagnostic accuracy in imaging of the head. Research presented by Dr. Zbijewski shows that high-speed Monte Carlo methods can be used for high-quality scatter correction, and combined with a comprehensive framework for correction of artifacts arising from lag, beam hardening, veiling glare, and other sources of image degradation, can yield image quality suitable to imaging of subtle pathology such as intracranial hemorrhage and traumatic brain in jury.
— J. Web Stayman et al., “Integration of Component Knowledge in Penalized Likelihood Reconstruction with Morphological and Spectral Uncertainties.” By extending the framework for Known-Component Reconstruction (KCR) to deformable objects and a polyenergetic x-ray beam, research presented by Dr. Stayman offers to improve image quality and reduce radiation dose in CT-guided procedures such as needle biopsy.
— S. Tilley et al., “Iterative CT Reconstruction Using Models of Source and Detector Blur and Correlated Noise.” Research presented by Steve Tilley shows how model-based reconstruction can be improved by incorporating models for blur and noise correlation, showing particular advantage over conventional models for scanner configurations in which focal spot blur is a significant source of image degradatation.
— A. S. Wang et al., “Nesterov’s Method for Accelerated Penalized Likelihood Statistical Reconstruction for C-arm Cone-Beam CT.” For image-guided surgery, the ability to form high-quality cone-beam CT using a mobile C-arm offers important advances in surgical precision and safety. Research presented by Adam Wang shows that not only can advanced reconstruction methods be used to improve CBCT image quality for soft tissue imaging and reduce radiation dose, but also that such images can be formed on practical time scales in the operating room (less than 2 minutes) using Nesterov’s method for accelerated convergence.
New 3D Image Reconstruction Methods Improve Image Quality and Reduce Dose

Research underway in The I-STAR Lab spearheaded by Dr. Web Stayman offers to advance the performance of CT and cone-beam CT in diagnostic and image-guided procedures. Among the breakthroughs are three forms of penalized likelihood (PL) model-based image reconstruction that overcome conventional barriers to image quality and dose and present potentially new paradigms for CT image acquisition and reconstruction that knowledgeably include prior information and a specification of the imaging task.
Task-Driven Imaging. Over the last decade, task-based image quality assessment has formed an area of active research, including the use of task-based detectability index for the design and optimization of new cone-beam CT systems for diagnostic and image-guided procedures. Recent research takes task-based metrics from the realm of image quality assessment to a position directly within the imaging chain – as the objective function to be optimized in the process of image acquisition and reconstruction. The resulting Task-Driven Imaging method presents a new paradigm for technique optimization with implications for new acquisition and reconstruction techniques — e.g., optimal source-detector orbits, as reported at The Fully 3D Meeting 2013). Recent research includes testing and evaluation of Task-Driven Imaging on a robotic C-arm for image-guided interventions.
PIRPLE. Many imaging scenarios – especially in image-guided interventions – involve repeat image acquisitions. For example, in image-guided radiotherapy or surgery, the patient receives a planning CT followed by a number of images acquired for interventional guidance. The PIRPLE algorithm (Prior-Image-Registered Penalized Likelihood Estimation) incorporates the prior image within the up-to-date image reconstruction process via an additional penalty and regularization term. The approach demonstrates the potential for major improvement in image quality and reduction of dose. Recent work includes extension to deformable prior images (dPIRPLE) and evaluation in clinical studies.
KCR. The “Known-Component Reconstruction” (KCR) framework forms the 3D image in two parts – an unknown background component (e.g., patient anatomy) and a known component (e.g., implant or interventional device) whose shape and content are specified either exactly or parametrically. In solving a joint registration (of the known component) and reconstruction (of the component and background), KCR demonstrates major reduction in noise and artifacts that plague conventional imaging methods, especially in the presence of heavy metal components, such as screws, plates, and prosthetics. Original findings were reported in IEEE-TMI, and recent advances extend KCR to deformable components (dKCR, such as needles or cochlear implants) and account for effects of the polyenergetic x-ray beam.
1st and 2nd Place Paper Awards at SPIE 2014

Students from the I-STAR Lab earned 1st and 2nd place paper awards at the SPIE 2014 Medical Imaging conference in San Diego.
Sureerat (“Ja”) Reaungamornrat won the 1st-place student paper award in the Image-Guided Procedures conference as well as the SPIE Young Scientist Award. Her paper entitled “Deformable registration for image-guided spine surgery: preserving rigid body vertebral morphology in free-form transformations.” described a method for constraining 3D deformable image registration in a manner that preserves the morphology of rigid bodies (e.g., spinal vertebrae) moving within a context of surrounding soft tissues.(SPIE Abstract 9036-27, Page 138)
Jennifer Xu won the 2nd-place student paper award in the Physics of Medical Imaging conference. Her paper entitled “Cascaded Systems Analysis of Photon Counting Detectors.” described a cascaded systems model for noise, spatial resolution, and detective quantum efficiency (DQE) of photon counting detectors, providing an analytical basis for understanding the effects of charge sharing and detector threshold and validating the theoretical predictions in comparison to measurements with the Philips MicroDose photon counting system. (SPIE Abstract 9033-70, Page 20)
I-STAR Talks and Posters — SPIE 2014
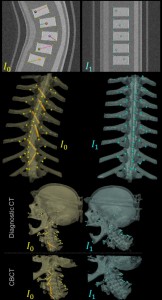
Seven presentations from the I-STAR Lab report advances in imaging physics: SPIE Medical Imaging 2014
Dang et al., Regularization design and control of change admission in prior-image-based reconstruction.(Tuesday Feb 18, 10:10am)
Reaungamornrat et al., Deformable registration for image-guided spine surgery: preserving rigid body vertebral morphology in free-form transformations. (Wednesday, February 19 – 10:30am)
</p
Wang et al., Patient-specific minimum-dose imaging protocols for statistical image reconstruction in C-arm cone-beam CT using correlated noise injection.(Thursday, February 20 – 8:00am)
Xu et al., Cascaded Systems Analysis of Photon Counting Detectors.(Thursday, February 20 – 1:20pm)
Zbijewski et al., High-performance soft-tissue imaging in extremity cone-beam CT. (Thursday, February 20 – 4:50pm)
Stayman et al., Generalized Least-Squares CT Reconstructionwith Detector Blur and Correlated Noise Models.(Wednesday, February 19 – 5:30-7:30pm)
Uneri et al., Dual-Projection 3D-2D Registration for Surgical Guidance: Preclinical Evaluation of Performance and Minimum Angular Separation.(Wednesday, February 19 – 5:30-7:30pm)
LevelCheck wins 2013 Spine Technology Award
Localization of target vertebrae is essential to effective spine surgery, but confident identification of vertebrae in intraoperative radiographs can challenge even experienced surgeons and radiologists. Manual “level counting” presents a time-consuming, error-prone process with which spine surgeons contend every day, and wrong-level surgery is still encountered at an unacceptably high rate of occurrence.
The LevelCheck algorithm was developed at Johns Hopkins University as an assistant and “independent check” on spine level localization. The method combines a robust 3D-2D registration alogirthm with high-speed computing to automatically identify vertebral levels in intraoperative x-ray images. The process robustly registers vertebral labels – along with any other information defined in preoperative CT – to C-arm or mobile x-ray radiographs in just a few seconds. Initial studies tested the algorithm in simulations drawn from The Cancer Imaging Archive. Preclinical studies validated performance in cadaver, including the effects of gross anatomical deformation. Clinical studies are now underway.
The work was awarded the 2013 Spine Technology Award by Orthopedics This Week and announced at the 2013 North American Spine Society.
The algorithm was developed in the I-STAR Lab by Yoshito Otake and collaborators in Orthopaedic Surgery (Dr. Jay Khanna and colleagues) and Neurosurgery (Dr. Ziya Gokaslan and colleagues) at Johns Hopkins University.
The LevelCheck algorithm was reported in two articles:
— Y. Otake et al., “Automatic localization of vertebral levels in x-ray fluoroscopy using 3D-2D registration: a tool to reduce wrong-site surgery,” Phys. Med. Biol. 57(17): 5485-5508 (2012).
— Y. Otake et al., “Robust 3D-2D Image Registration: Application to Spine Interventions and Vertebral Labeling in the Presence of Anatomical Deformation,” Phys. Med. Bio. 58 (23) 8535-8553 (2013). (pdf)
Congratulations to Yoshi and the LevelCheck team
I-STAR Talks — RSNA 2013
Five presentations from the I-STAR Lab and collaborators report advances in imaging physics: (talks)
— Radvany, Cay, et al., Quantitative Assessment of Metal Artifact Reduction in C-Arm Cone-Beam CT Guidance of Neurovascular Interventions (Mon Dec 02 3:00 – 4:00PM Rm S403B)
— Zbijewski et al., Cone-Beam CT with Sparse Arrays of Photon Counting Silicon Strip Detectors: Reconstruction, Performance Characterization, and Application to Dual-Energy Imaging (Tue Dec 03 10:30 – 10:40AM)
— Thawait et al., Use of a Dedicated Extremity Cone-beam CT Scanner for Evaluation of the Weight-bearing and Non-weight-Bearing Knee (Tue Dec 03 10:50 – 11:00AM Rm S403A)
— Stayman et al., Imaging-Task-Optimized, Source-Detector Trajectory Design and Reconstruction in 3D Interventional Imaging (Tue Dec 03 3:00 – 3:10PM)
— Wang et al., Synthetic Cone-Beam CT for Determining Patient- and Task-Specific Minimum-Dose Techniques in Repeat Scans (Fri Dec 06 12:00 – 12:10PM)
Congratulations, Dr. Gang!

Grace Gang successfully defended her PhD dissertation entitled, Task-based imaging performance in 3D x-ray tomography: Noise, detectability, and implications for system design. Grace’s work encompasses four peer-reviewed and several conference presentations, including First-Place at the 2013 AAPM Young Investigators Symposium ().
Among the breakthrough findings of her work:
— Incorporation of anatomical background noise in a generalized description of task-based detectability
— Validation of task-based model performance in comparison to human observers
— Extension of task-based modeling to dual-energy CT
— Extension of task-based modeling to iterative 3D image reconstruction
Grace’s examining committee included Dr. John Boone (UC Davis), Dr. Martin Yaffe (University of Toronto), Dr. Mike Joy (University of Toronto), Dr. Kristy Brock (University of Michigan), and Dr. Jeff Siewerdsen (Johns Hopkins University).
Conjuring Demons…
Three papers from the I-STAR Lab extend the Demons algorithm for deformable image registration to new dimensions and applications.
— S. Nithiananthan et al., Extra-dimensional Demons: A method for incorporating missing tissue in deformable image registration.
Med. Phys. 39 (9) (2012). (link)
Conventional deformable image registration can be confounded by the removal of tissue or the introduction of surgical instrumentation between the original (preoperative “moving”) image and the target (intraoperative “fixed”) image. By treating the 3D registration as a 4D registration, where the fourth or higher dimensions allow for motion into and out of the moving image, the Extra-Dimensional Demons (XDD) method is shown to accurately model such effects and provide accurate registration for image-guided interventions.
— A. Uneri et al., Deformable registration of the inflated and deflated lung in cone-beam CT-guided thoracic surgery: Initial investigation of a combined model- and image-driven approach.
Med. Phys. 40 (1) (2013). (link)
In thoracic surgery, the lung is often purposely collapsed for resection of a target lesion, but a surgeon’s ability to accurately localize the target can be confounded by gross deformation and nodules that are too small to see in thoracoscopy or even feel with one’s fingertips. By combining a mesh-driven model with the Demons algorithm, this paper reports a registration algorithm that solves the large deformation between the inflated and deflated lung to a level of geometric precision sufficient to guide the surgeon confidently to target nodules.
— S. Reuangamornrat et al., Deformable image registration for cone-beam CT guided transoral robotic base-of-tongue surgery.
Phys. Med. Biol. 58 (2013). (link)
Transoral robotic surgery (TORS) offers a promising new treatmetn of base of tongue cancer, but the the gross deformation between preoperative images (mouth closed, tongue in repose) and the intraoperative setup (mouth open, tongue retracted) limits the application of conventional guidance. By combining intraoperative cone-beam CT and a hybrid registration algorithm that combines a Gaussian mixture model with the Demons algorithm, this paper shows the ability to geometrically align images of the tongue to within ~1-3 mm.
Start Your Engines! I-STARs Head to Indy for AAPM 2013
Grace Gang reports breakthrough work in modeling and optimization of 3D image quality in statistical model-based image reconstruction, extending a cascaded systems analysis framework to prediction of noise, spatial resolution, and detectability for this novel class of important new reconstrution techniques. Grace’s talk is included in the Young Investigators’ Symposium:
— G. Gang et al.,Modeling Nonstationary Noise and Task-Based Detectability in CT Images Computed by Filtered Backprojection and Model-Based Iterative Reconstruction
Jennifer Xu reports a cascaded systems analysis framework for photon counting detectors applied to spectral and tomographic imaging, including aspects of noise, thresholding, energy resolution, and charge sharing. Her work helps to open a new window on understanding and optimizing imaging performance in photon counting CT.
— J. Xu et al., Cascaded Systems Analysis of a Silicon-Strip Photon Counting CT System
Dr. Jeff Siewerdsen and Dr. Bob Nishikawa Chair a scientific symposium on Image Quality Models in Advanced CT Applications, including spectral / dual-energy imaging, tomosynthesis and cone-beam CT, iterative reconstructin, phase-contrast CT, and model observers for volumetric image data. Invited speakers include Dr. Siewerdsen (Johns Hopkins University), Dr. Nishikawa (University of Chicago), Dr. Cunningham (University of Western Ontario), Dr. Chen (University of Wisonsin), and Dr. Bochud (Universitaire Vaudois).
CONGRATULATIONS, Dr. Nithiananthan!

Sajendra Nithiananthan successfully defended his PhD dissertation,Demons Deformable Registration for Intraoperative Cone-Beam CT Guidance of Head and Neck Interventions. Sajendra’s work included the following three peer-reviewed journal articles as well as several conference proceedings, talks, and posters:
— S. Nithiananthan et al.,“Demons deformable registration for cone-beam CT-guided procedures in the head and neck: Convergence and accuracy,” Med. Phys. 36(10): 4755-4764 (2009).
— S. Nithiananthan et al.,”Demons deformable registration of CT and cone-beam CT using an iterative intensity matching approach,” Med. Phys. 38(4): 1785 – 1798 (2011).
— S. Nithiananthan et al., “Extra-dimensional Demons: A method for incorporating missing tissue in deformable image Registration,” Med. Phys. 39(9):5718-5731 (2012).
CARS 2013 – Heidelberg, Germany
Four presentations from the I-STAR Lab report advances in 3D-2D image registration, image reconstruction, image-guided surgery, and diagnostic imaging:
— Y. Otake et al., Automatic localization of vertebral levels in C-arm fluoroscopy: Evaluation of the LevelCheck algorithm in a preclinical cadaver study with realistic tissue deformation
— Y. Otake et al., Verification of surgical product and detection of retained foreign bodies using 3D-2D registration in intraoperative mobile radiographs
— A. S. Wang et al., Soft tissue visibility and dose reduction in mobile C-arm cone-beam CT using advanced 3D image reconstruction
— J. H. Siewerdsen et al., Advanced imaging capability in dedicated cone-beam CT of musculoskeletal extremities
Research in 3D Image Reconstruction Presented at Fully 3D
Four presentations from the I-STAR Lab report advances in 3D image reconstruction:
— J. W. Stayman et al., Task-Based Trajectories in Iteratively Reconstructed Interventional Cone-Beam CT
— W. Zbijewski et al., Volumetric Imaging with Sparse Arrays of Photon Counting Silicon Strip Detectors
— A. S. Wang et al., Statistical Reconstruction for Soft Tissue Imaging with Low Dose C-arm Cone-Beam CT
— H. Dang et al., Joint Estimation of Deformation and Penalized-Likelihood CT Reconstruction Using Previously Acquired Images
SPIE Medical Imaging 2013
Ten presentations from the I-STAR Lab and collaborators report advances in imaging physics and image-guided interventions:
Physics of Medical Imaging
— High energy x-ray phase contrast imaging using glancing angle grating interferometers, D. Stutman et al. (Wednesday, February 13 – 8:20 am)
— Noise reduction in material decomposition for low-dose dual-energy cone-beam CT, W. Zbijewski et al. (Wednesday, February 13 – 10:30 am)
— Soft-tissue imaging in lowdose, C-arm cone-beam CT using statistical image reconstruction, A. Wang et al. (Wednesday, February 13 – 1:40 pm)
— Modeling and control of nonstationary noise characteristics in filtered-backprojection and penalized likelihood image reconstruction,G. Gang et al. (Wednesday, February 13 – 2:00 pm)
— Overcoming nonlinear partial volume effects in known-component reconstruction of cochlear implants, W. Stayman et al. (Wednesday, February 13 – 4:10 AM)
Molecular and Functional Imaging
— Peripheral quantitative CT (pQCT) using a dedicated extremity cone-beam CT scanner, A. Muhit et al. (Sunday, February 10 – 8:20 am)
Image-Guided Procedures
— (Student Paper Award Finalist) Deformable registration for cone-beam CT guidance of robot-assisted, trans-oral base-of-tongue surgery, S. Reaungamornrat et al. (Tuesday, February 12 – 4:10 pm)
— (Poster Award – Honorable Mention) Deformable image registration with content mismatch: A Demons variant to account for added material and surgical devices in the target image, S. Nithiananthan et al. (Tues-Wed poster sessions, February 12-13)
— Intraoperative imaging for patient safety and QA: Detection of intracranial hemorrhage using high-quality C-arm cone-beam CT, S. Schafer et al. (Tues-Wed poster sessions, February 12-13)
— Model-based cone-beam CT reconstruction for image-guided minimally invasive treatment of hip osteolysis, Y. Otake et al. (Wednesday, February 13 – 2:40 pm)
A Tale of Two Trackers
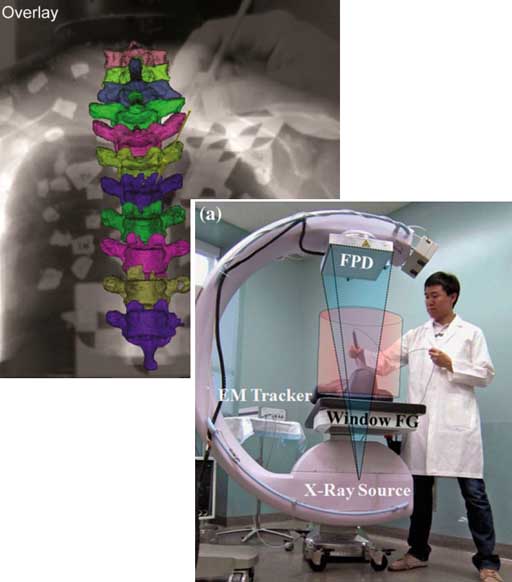
Two papers appearing in the International Journal of Computer-Assisted Radiology and Surgery (IJCARS) report on the development of new surgical tracking configurations at the I-STAR Lab.
First, Sureerat Reaungamornrat’s paper describes the “Tracker-on-C” configuration in which a tracker is mounted directly on an intraoperative C-arm. The work demonstrates improved line of sight and increased registration accuracy. Additional functionality includes “virtual fluoroscopy” (real-time calculation of DRRs from any C-arm angulation) and video augmentation (overlay of image and tracking data on a video scene derived from the tracker) for improved workflow and reduced radiation dose. (IJCARS) and (SPIE)
Second, Jongheun Yoo’s paper on the “Tracker-in-Table” configuration uses an x-ray compatible electromagnetic tracker incorporated directly within the operating table. The prototype “Window FG” field generator from NDI was configured to allow fluoroscopy and cone-beam CT. The system provides a large measurement volume consistent with a number of surgical navigation scenarios and a method for registration that is robust against the presence of the nearby rotating C-arm. (IJCARS)
RSNA 2012
Presentations on advanced imaging techniques from the I-STAR Lab and collaborators:
W. Zbijewski et al. “Advanced Noise Reduction and Statistical Reconstruction Techniques for Low-Dose Dual-Energy Cone-Beam CT” (PDF – coming soon)
A theoretical basis for image noise in DE-CBCT combined with advanced iterative reconstruction techniques probe the low-dose, low-concentration limits of dual-energy CT image quality.
— Wednesday, November 28 – 10:40 AM (Room S404AB, Talk #SSK17-02)
J. Web Stayman et al. “Advanced Statistical Reconstruction and Incorporation of Prior Knowledge for C-Arm Cone-Beam CT in Image-Guided Interventions” (PDF – coming soon)
A novel framework for model-based reconstruction combines statistical models of image noise with prior image information to yield high-quality, low-dose cone-beam CT in image-guided interventions.
— Thursday, November 29 – 10:50 AM (Room S404AB, Talk #SSQ18-03)
D. Stutman et al. “Development of X-Ray Phase-Contrast Imaging for Large Joints” (PDF – coming soon)
A novel approach to differential phase contrast CT allows imaging at higher x-ray energy than previously achieved and propels application to imaging of large joints in musculoskeletal radiology.
— Monday, November 26 — 11:10 AM (Room S403A, Talk #SSC14-05)
X-RAYS CAN’T HAVE ALL THE FUN!
Dr. Siewerdsen moderates the RSNA-AAPM Symposium. IMAGING SPEED DEMONS!
C. A. Mistretta, “Breaking Angiographic Speed Limits: Accelerated 4D MRA and DSA”
M. Tanter, “Ultrasound Goes Supersonic: Very-High-Speed Plane Wave Transmission Imaging”
— Thursday, November 29 – 1:00 PM (Arie Crown Theatre)
Imaging Physics TRIPLE PLAY
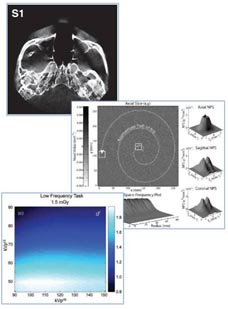
Three papers on image quality in cone-beam CT span from practical to sublime.
J. Xu et al. “Technical assessment of a cone-beam CT scanner for otolaryngology imaging: Image quality, dose, and technique protocols”
A rigorous technical assessment of a new cone-beam CT system for ENT examines image quality and dose. In collaboration with industry partners, the technical assessment identified new scan protocols that reduced radiation dose by 30% or more.
A. Pineda et al. “Beyond noise power in 3D computed tomography: The local NPS and off-diagonal elements of the Fourier domain covariance matrix”
Answering a long-standing challenge to go off the diagonal, this paper examines basic assumptions in noise-power spectrum analysis and examines non-stationarity of image noise as evident in off-diagonal elements of the Fourier covariance matrix. Check out the paper andvideoAir, videoBowtie, and videoNoBowtie.
EDITOR’S PICK! G. Gang et al. “Cascaded systems analysis of noise and detectability in dual-energy cone-beam CT”
Modeling of NPS, NEQ, and task-based detectability is extended to dual-energy CT, providing a theoretical framework for optimizing imaging and reconstruction protocols and minimizing radiation dose.
HOT TOPICS for Summer

HOT TOPICS for Summer
A series of talks on image science, 3D image reconstruction, diagnostic imaging, and image-guided interventions marks the I-STAR summer schedule.
The 2nd Intl. Conf. on CT (Salt Lake City UT, June 24-27, 2012)
– Stayman et al. “Information Propagation in Prior-Image-Based Reconstruction”
– Zbijewskit et al. “CT Reconstruction Using Spectral and Morphological Prior Knowledge: Application to Imaging the Prosthetic Knee”
The University of Wisconsin, Department of Medical Physics (Madison WI, June 18, 2012)
– Siewerdsen et al. “Now You C It: Image Science and Applications of Cone-Beam CT”()
The National Academy of Sciences (Bethesda MD, June 28, 2012)
DASER (DC Art Science Evening Rendezvous)
Cultural Program
– Siewerdsen et al. “Images Are Numbers” ()
The 54th AAPM Annual Meeting (Charlotte NC, July 29 – August 2, 2012)
– Muhit et al. “Diagnostic Image Quality Evaluation of a Dedicated Extremity Cone-Beam CT Scanner: First Clinical Results”
– Zbijewski et al. “High-Quality Imaging in the Presence of Surgical Instrumentation [Best in Physics!] “
– Stayman et al. “Information Source Mapping in Prior-Image-Based Reconstruction”
– Stayman et al. “Fundamentals of Statistical / Iterative Image Reconstruction”
– Siewerdsen et al. “Image-Guided Oncologic Surgery”
– Kessler, Sonke, and Siewerdsen, “Image Acquisition and Processing for Adaptive Radiotherapy”
– Siewerdsen et al. “Assessment of Image Quality in the New CT”
EXTRA! EXTRA! I-STAR Research in the News:
– News-Line for Radiology Professionals
– Diagnostic Imaging
– ADVANCE for Imaging & Radiation Oncology
KCR Algorithm Builds Steam
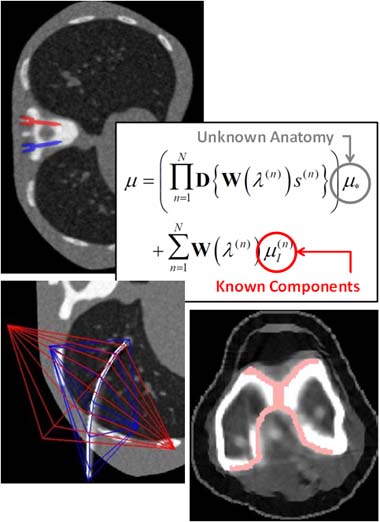
Web Stayman’s “Known-Component Reconstruction” (KCR) algorithm demonstrates an exciting new approach to 3D image reconstruction in 4 publications: 1.) the original concept reported at The Fully 3D Meeting (Potsdam Germany); 2.) an upcoming IEEE-TMI paper; 3.) a KCR variant allowing for deformable components (“dKCR”) reported at SPIE (San Diego CA); and 4.) extension of the model to polyenergetic spectra and application to large, challenging, metallic implants (knee replacement) at The International CT Meeting (Salt Lake City UT).
The KCR method is much more than a metal artifact correction method. It is a novel approach to 3D image reconstruction in which the image is treated in two parts – an unknown anatomical background and a known (or partly known) component therein – and a joint estimation is computed in successive iterations: reconstruction of the anatomical background and registration of the component. Studies demonstrate that the registration tends to converge quickly, and as the component locks in with sub-voxel precision in the attenuation map, artifacts that normally confound image quality in the presence of metal implants instead melt away. The resulting 3D image reconstruction exhibits a dramatic increase in image quality, potentially allowing visualization right up to the surface of the implant. Variations in development include model-based reconstruction with a polyenergetic beam, deformable component models, and statistically-known component models.
Prototype Cone-Beam CT Scanner Enters First Clinical Study
A novel cone-beam CT scanner dedicated to extremity imaging has been developed at Johns Hopkins University in collaboration with Carestream Health. Development of the prototype scanner included task-based imaging performance assessment and modeling combined with a recognition of clinical challenges and potential improvements in space, workflow, and dose. The scanner is self-shielded, occupies ~ 1 sq. m. footprint, and incorporates imaging protocols optimized for bone and soft-tissue visualization. Among the key features of the scanner is the capability to image the weight-bearing knee and lower extremities, opening new capabilities for diagnosis of a variety of impingement syndromes. Other capabilities include protocols for combined radiography, fluoroscopy, and cone-beam CT on the same platform, functional / morphological analysis of joint space and tissue integrity, and dual-energy CT.
The system entered the first IRB-approved clinical study in February, 2012, including imaging of the upper and lower extremities. Potential applications include musculoskeletal radiology, orthopaedic trauma, surgical planning and treatment assessment, and rheumatological imaging. Thanks to Dr. John Carrino for leading the clinical study and to Dr. Simon Mears, Dr. Ken Means, Dr. Frank Frassica, and Dr. Carl Johnson for participation in the study.
I-STAR Presentations Blitz at SPIE 2012

The Super Bowl isn’t the only show in early February… SPIE 2012 (San Diego, Feb. 4-9) includes TEN presentations from the I-STAR Lab on a spectrum of research in medical imaging physics and image-guided interventions. Presentations available at I-STAR Presentations, and pre-prints of the papers can be found at I-STAR Publications.
Photos and fun from SPIE 2012 can be seen on PIcasa.
PHYSICS OF MEDICAL IMAGING
— Gang et al. “Theoretical Framework for the Dual-Energy Cone-Beam CT Noise-Power Spectrum, NEQ, and Tasked-Based Detectability Index”
— Zbijewski et al. “Dose and Scatter Characteristics of a Novel Cone-Beam CT System for Musculoskeletal Extremities”
— Stayman et al. “Model-Based 3D Image Reconstruction of Objects with Inexactly Known Components”
— Ding et al. “Reconstruction using prior images on noisy, sparse tomographic data”
IMAGE-GUIDED INTERVENTIONS
— Lee et al. “Incorporation of Prior Knowledge for Region-of-Change Imaging from Sparse Scan Data in Image-Guided Surgery”
— Uneri et al. “Deformable Registration of the Inflated and Deflated Lung for Cone-Beam CT-Guided Thoracic Surgery”
— Reaungamornrat et al. “Tracker-on-C for Cone-Beam CT-Guided Surgery: Evaluation of Geometric accuracy and Clinical Applications”
— Liu et al. “A Clinical Pilot Study of a Modular Video-CT Augmentation System for Image-Guided Skull Base Surgery” (Poster Session)
— Otake et al. “Automatic Localization of Target Vertebrae in Spine Surgery Using Fast CT-to-Fluoroscopy (3D-2D) Image Registration”
— Schafer et al. “High-Performance C-arm Cone-Beam CT Guidance of Thoracic Surgery”
PANEL DISCUSSION: CT IMAGE QUALITY ASSESSMENT (Joint PHYSICS-PERCEPTION Worskhop)
— Siewerdsen,. “Evaluation of Imaging Performance in CT: Measurement and Modeling for the Development of Novel CT Systems”
Webcast of the Month: Fundamentals of 3D Filtered Backprojection
Dr. Siewerdsen’s seminar at the annual meeting of the AAPM (Vancouver BC) was selected as the AAPM Virtual LIbrary “Webcast of the Month”:
— Fundamentals of 3D Filtered Backprojection
— Virtual Library presentation available online at:
— PDF slides are available in I-STAR Presentations
TREK Software for Image-Guided Surgery Turns 1.0
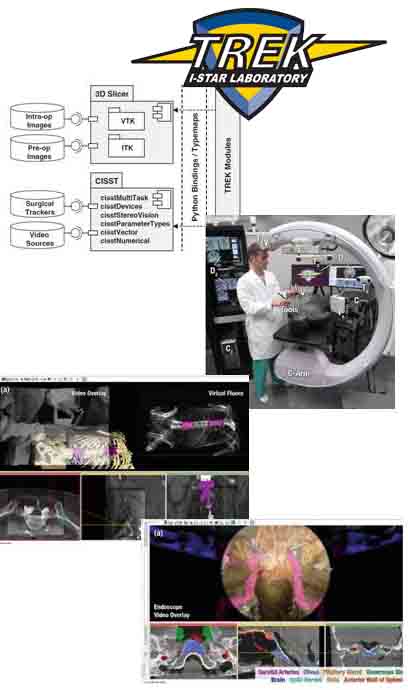
Within one year of its creation, the TREK software architecture has enabled a broad spectrum of research in image-guided surgery. Created by Ali Uneri in ongoing collaboration between the Departments of Biomedical Engineering (Jeff Siewerdsen), Computer Science (Russ Taylor), and Surgery (Drs. Khanna, Reh, Gallia, and Sussman) at Johns Hopkins University, TREK turns “1.0” years old next month. The software binds open-source libraries from the Hopkins CISST resources with a 3D Slicerfront end for modular, application-specific system integration and interface development. Among the projects, presentations, and publicationsspringing from the TREK platform in its first year of deployment are:
— High-precision registration of endoscopic video with cone-beam CT (D. Mirota et al., SPIE 2011)
— Quantitative investigation of surgical performance in cone-beam CT-guided skull base surgery (S. Lee et al., NASBS 2011)
— The Tracker-on-C configuration for surgical navigation, virtual fluoroscopy, and video augmentation (S. Reuangamornrat et al., CARS 2011)
— An EM Tracker-in-Table for image-guided surgery (J. Yoo et al., CARS 2011)
— Image quality in cone-beam CT-guided spine surgery (S. Schafer et al., Med Phys 2011)
— The role of antiscatter grids in mobile C-arm cone-beam CT (S. Schafer et al., AAPM 2011 and Med Phys 2011)
— Automatic labeling of vertebrae levels in image-guided spine surgery. (Y. Otake et al., SPIE 2012)
— Clinical pilot studies of video-CT registration. (W. Liu et al., SPIE 2012)
— Region-of-change imaging in cone-beam CT-guided surgery (J. Lee et al, SPIE 2012.)
— Mobile C-arm cone-beam CT for guidance of thoracic surgery (S. Schafer et al., AAPM 2011 and SPIE 2012)
— Deformable registration in cone-beam CT-guided thoracic surgery (A. Uneri et al., SPIE 2012)
The paper detailing the TREK architecutre was published in the International Journal of Computer-Assisted Radiology and Surgery (IJCARS) — see I-STAR Publications, Uneri et al., IJCARS 7(1): 159-173 (2012).
Noise, Noise, Noise: A Comprehensive Image Noise Model Guides New Scanner Design
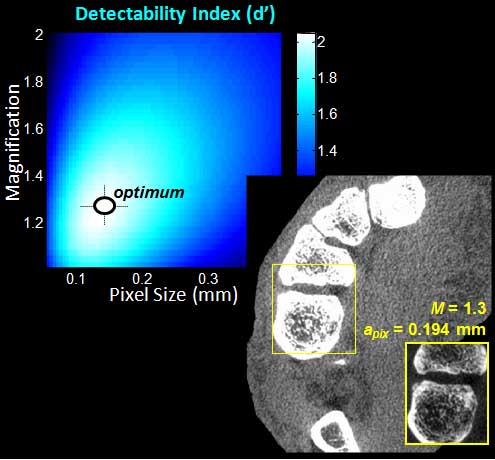
A recent article in the Medical Physics Journal applies cascaded systems analysis of the Noise-Power Spectrum (NPS) and Noise-Equivalent Quanta (NEQ) to task-based analysis of a new cone-beam CT scanner for musculoskeletal (MSK) extremity imaging. The model is fairly comprehensive in combining numerous factors governing noise and spatial resolution, including: quantum noise, electronic noise, background anatomical noise, etc. The paper also addresses the factors governing spatial resolution, such as x-ray focal spot size, system geometry, detector pixel size, etc. Bringing these factors together in a task-based model for detectability index provided a basis for optimization of system design, including tube selection, detector selection, system geometry, acquisition technique, and reconstruction technique. The theoretical results agreed qualitatively with various imaging tasks performed in cadavers – for example, detection of bone details and discrimination of soft-tissues. The results guided the construction of a new cone-beam CT scanner dedicated to extremity imaging, now deployed at Johns Hopkins Hospital.
The paper (pdf) is available in I-STAR Publications (Prakash et al., “Task-based modeling and optimization of a cone-beam CT scanner for musculoskeletal imaging,” Med. Phys. 38(10): 5612-5629 (2011).
Double-Feature of Papers in Medical Physics Journal earn “Editor’s Pick” Recognition
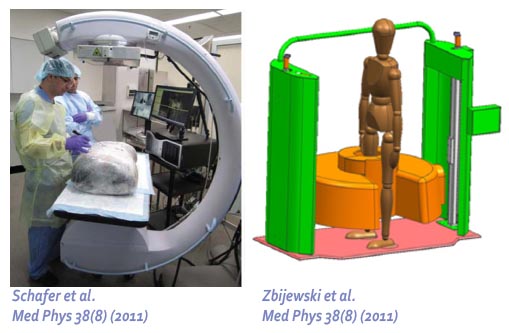
Two of the three “Editor’s Picks” for the Medical Physics Journal (Volume 38(8)) are papers from the I-STAR Lab:
— Schafer et al., “Mobile C-arm cone-beam CT for guidance of spine surgery…”describes the identification of low-dose CBCT protocols for 3D C-arm imaging in spine surgery (pdf).
— Zbijewski et al. “A dedicated cone-beam CT system for musculoskeletal extremities imaging…” describes the design and imaging performance of the CBCT prototype now entering trials at Johns Hopkins Hospital. (pdf)
I-STAR Lab Summer Barbecue a Blast!

The I-STAR team took a break from the lab to enjoy the sunshine at Rocks State Park. Highlights of the day included:
— Kayaking on Deer Creek
— The first annual “Real Angry Birds” contest
— A grand prize: I-STAR Lab custom skateboard
— Scenic views from the King & Queen’s Chair as Dr. Zbijewski shows us all the ropes in rock climbing.
Summer Heats Up at AAPM 2011, including 11 I-STAR Presentations

Eleven I-STAR presentations at AAPM 2011 in Vancouver, British Columbia, run the gamut in imaging research, including fundamental imaging physics, 3D image reconstruction, diagnostic imaging, and image-guided surgery:
— “Fundamentals of 3D Image Reconstruction” (Jeff Siewerdsen)
— “Image Guidance in Video-Assisted Thoracoscopic Surgery (VATS) using a Mobile C-Arm for Cone-Beam CT” (Sebastian Schafer)
— “Turning People into Numbers: A Quantiative Perspective on Image Acquisition” (Jeff Siewerdsen)
— “Deformable Image Registration in the Presence of Excised Tissue: A Modified Demons Algorithm for Cone-Beam CT-Guided Surgery” (Sajendra Nithiananthan)
— “Contrast-Enhanced Dual-Energy Cone-Beam CT for Musculoskeletal Radiology” (Wojtek Zbijewski)
— “Model-based Known Component Reconstruction for Computed Tomography” (Web Stayman)
— “Using Prior Images with Registration in Penalized Likelihood Estimation for CT with Sparse Data” (Web Stayman)
— “Task-Based Modeling and Optimization of a Dedicated Cone-Beam CT Scanner for Musculoskeletal Imaging” (Prakhar Prakash) – Best in Physics Award!
— “A Cascaded Systems Model for Imaging Performance and Task-Based Optimization in Dual-Energy Cone-Beam CT” (Grace Gang)
— “Performance Characterization of a Cone-Beam Computed Tomography System for Musculoskeletal Imaging” (Paul DeJean, Wojtek Zbijewski)
— “Grids Revisited: The Effect of Antiscatter Grids on Image Quality and Dose in Mobile C-Arm Cone-Beam CT” (Sebastian Schafer)
“KCR” Technique Allows Imaging in the Presence of Implants
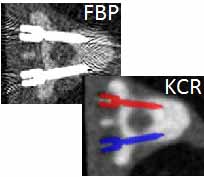
Dr. Web Stayman will present a new 3D image reconstruction technique (referred to as Known-Component Reconstruction, KCR) at The Fully 3D Meeting in Potsdam, July 11-15. The KCR algorithm allows nearly artifact-free imaging in the presence of metallic implants, whereas conventional reconstruction methods often suffer from severe artifacts. By including prior information on the shape of the implant and simultaneously registering and reconstructing the object within an unknown background of patient anatomy, KCR is shown to provide a dramatic improvement over conventional filtered-backprojection and various metal artifact reduction approaches. Results are shown in the context of spine surgery, where KCR allows imaging in the presence of spine screws and allows confident visualization of devices in proximity to the spinal cord and other critical structures. The method creates an interesting new framework for image reconstruction in a broad spectrum of applications in which known components are present in the image – for example, medical devices such as needles, screws, rods, and prosthetic implants.
I-STARs at CARS (Berlin)

Four presentations at CARS Berlin, June 22-25, highlight recent advances in image-guided surgery and diagnostic radiology from the I-STAR Lab.
Dr. Sebastian Schafer will present results in the use of C-arm cone-beam CT to guide thoracic surgeons to subpalpable lung tumors (abstract).
The culmination of two Master’s theses in Computer Science will also be presented:
Sureerat Reaungamornrat’s implementation of a novel tracker-on-C-arm configuration (abstract), and
Jongheun Yoo’s work on an x-ray compatible electromagnetic tracker (abstract).Best Student Poster Award!
A fourth presentation shows the latest development of a dedicated cone-beam CT scanner for musculoskeletal extremities, orthopaedics imaging, and rheumatology:
Dr. John Carrino presents the development of the novel scanner prototype (abstract), now deployed for pilot studies at Johns Hopkins University.
Exercising Demons
Sajendra Nithiananthan and co-authors gave the popular “Demons” algorithm for 3D deformable registration a workout in a recent Medical Physics article (pdf). The conventional Demons algorithm relies upon the moving and fixed images having equal voxel value (“intensity”) for agiven material – for example, in registering one CT image to another. Registering CT to CBCT, however, violates this requirement, since CBCT voxels are often uncalibrated in Hounsfield units and suffer a variety of artifacts and inaccuracies. A straightforward application of the Demons algorithm in CT-CBCT registration is shown to result in significant spurious distortions of the image. A simple histogram match prior to registration helps but was similarly prone to distortion. By incorporating an iterative intensity match between CT and CBCT voxels directly within the Demons algorithm,Sajendra realized a new Demons variant that is free from spurious distortion, geometrically accurate to the level of the voxel size, and extremely robust against intensity differences and shading artifacts.
To Boldly Go… TREK Software Architecture for IGS

A new software architecture for image-guided surgery has been developed in the I-STAR Lab for integration of intraoperative 3D imaging with systems for surgical tracking, video augmentation, and analysis. Ali Uneri (PhD Student, Department of Computer Science) used open-source libraries for surgical navigation (Hopkins cisst libraries) bound to front-end visualization and analysis in 3D Slicer to achieve a flexible, modular architecture that can be rapidly adapted to various application-specific tasks and workflow scenarios. The software forms the platform for I-STAR research in surgical navigation in CBCT-guided procedures ranging from orthopaedic to skull base and thoracic surgery. The work was reported in proceedings (pdf) of the SPIE Medical Imaging Symposium 2011 (Orlando FL).
I-STAR Presentations Kick Off the New Year!

A flurry of upcoming conference presentations highlight a spectrum of I-STAR research:
— January 7: From Quarks to Cancer: The Role of Physics in Medicine (Dr. Jeff Siewerdsen, Einstein Fellowship Talk, American Center for Physics)
— January 15: A Dedicated Cone-Beam CT System for MSK Radiology (Dr. John Carrino, Orthopaedic Research Society, Long Beach CA)
— February 4: Cone-Beam CT Principles and Applications (Dr. Jeff Siewerdsen, Belgian Hospital Physicists Association, Charleroi Belgium)
— February 13: Demons Deformable 3D Image Registration for Image-Guided Surgery (Sajendra Nithiananthan, SPIE Medical Imaging, Orlando FL)
— February 13: Design and Performance of a Cone-Beam CT System for MSK Radiology (Dr. Wojtek Zbijewski, SPIE Medical Imaging, Orlando FL)
— February 13: High-Accuracy Registration of Endoscopic Video with Cone-Beam CT (Daniel J. Mirota, SPIE Medical Imaging, Orlando FL)
— February 14: TREK Software Architecture for System Integration in C-Arm CT-Guided Surgery (Ali Uneri, SPIE Medical Imaging, Orlando FL)
— February 15: Penalized Likelihood Reconstruction from Sparse Acquisition with Unregistered Priors and Compressed Sensing Penalties (Dr. Web Stayman, SPIE Medical Imaging, Orlando FL)
— February 18: Surgical Performance in Cone-Beam CT-Guided Skull Base Surgery (Dr. Stella Lee, North American Skull Base Society, Scottsdale AZ)
Tomosynthesis Team Tees Up!
Dr. Web Stayman leads a new collaborative project on advanced 3D image reconstruction for tomosynthesis . For thoracic imaging, tomosynthesis promises to overcome conventional limitations of radiographic image quality by providing 3D information from a small number of projections. Using advanced iterative 3D reconstruction methods, Dr. Stayman hopes to unlock a wealth of previously untapped potential in tomosynthesis, including improvements in image quality, incorporation of prior information, and reduction of radiation dose. The research leverages an aresenal of high-speed computational techniques developed in the I-STAR Lab for high-performance, practical implementation of iterative 3D reconstruction, some summarized here.
RSNA Triple Play
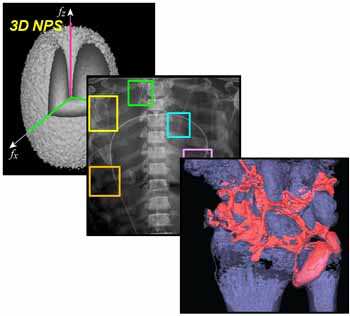
Dr. Jeff Siewerdsen presented three talks on behalf of the I-STAR Lab at the Annual Meeting of the Radiological Society of North America (RSNA). The first concluded an educational series on image quality in cone-beam CT. Reprints are available here. The second reported the development of a dual-energy radiography system using a wireless portable DR detector. The third presented the design and initial performance of a deciated cone-beam CT scanner for musculoskeletal extremities imaging. Photos from the RSNA meeting are available here.
Dr. Carrino – a Top Doc!

Baltimore Magazine’s 2010 list of top doctors includes Dr. John Carrinoamong the physicians identified as the best in the region – no small accomplishment, considering the caliber of hospitals and healthcare professionals in and around Baltimore. As Chief of the Section of Musculoskeletal Radiology at Johns Hopkins Hospital, Dr. Carrino is an renowned clinician and researcher in areas ranging from diagnostic imaging to interventional procedures. See the full article in Baltimore Magazine. Congratulations to our Top Doc!
U-Chicago – Hopkins Collaboration in PMB
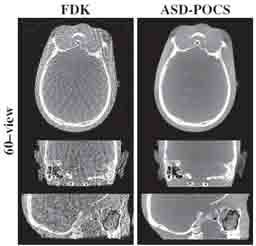
A recent article in The Journal of Physics and Medicine in Biology (Junguo Bian et al., “Evaluation of Sparse-View Reconstruction from Flat-Panel Detector Cone-Beam CT”) shows the latest results from collaboration between the University of Chicago and Johns Hopkins University. The work evaluates several advanced iterative reconstruction techniques operating on sparse projection sets, including expectation maximization, compressive sensing, and total variation minimization. Image quality is evaluated using real image data over a broad range of experimental conditions, and the potential for fast and/or low-dose cone-beam CT is quantified. While conventional filtered backprojection breaks down for sparse projection sets, the work points to the enormous potential of such iterative reconstruction techniques in the future of CT reconstruction. As of November 1, the paper is both a “Featured Article” and is among the MOST-READ articles in PMB over the last month. See the full article in The Journal of Physics and Medicine in Biology (PMB). The article was also cited in Medical Physics Web for its potential in low-dose cone-beam CT.
Extremities CT Scanner at BMES

At the annual meting of the Biomedical Engineering Society (BMES) in Austin TX, Yifu Ding presented the latest research in development of a dedicated cone-beam CT scanner for imaging of extremities. The scanner will provide high-resolution images with soft-tissue visibility for MSK radiology and orthopaedics. Trials are scheduled to begin at Hopkins in 2011. Watch Yifu’s interview online on .
Enduring Impact – Congratulations, Dr. Taylor!

I-STAR Collaborator Dr. Russ Taylor was awarded the 2010 MICCAI Society Enduring Impact Award by the Medical Image Computing and Computer Assisted Intervention Society at the 2010 MICCAI conference in Beijing, China. This prestigious award is given annually in recognition of research leadership. Dr. Taylor is a founding member of the MICCAI Society (http://www.miccai.org) and was named a MICCAI Fellow in 2009.
Congratulations to Russ on this much deserved award recognizing his extraordinary research and leadership in medical imaging and computer-assisted intervention!
I-STAR Lab Website Goes Live

Of course it did — you’re looking at it!
Our goal was simple functionality with useful content and fun.
Built using Dreamweaver with thanks to Valeria Costadoni for her expertise in laying out the site.
Ring the Bell!

I-STAR Collaborator Dr. Jay Khanna and the winning CBID Design Team participated in the NASDAQ closing bell ceremony! Dr. Khanna supervised Christopher Komanski, Nicolas Martinez, Evan Luxon, Jason Hsu and Stephanie Huang, whose team won numerous prizes in entrepreneurial competitions around the country in 2010, including Michelson Grand Prize and the Wharton Business Plan Competition. The team has launched Cortical Concepts, an endeavor based on an innovative spine screw “anchor” designed to provide improved fixation in patients with osteoporosis.
Watch the of Dr. Khanna, the CBID Team, family, and friends at the NASDAQ Closing Bell!
Aunt Minnie Article Reports I-STAR Research in High-Quality Imaging for the ICU

Aunt Minnie (auntminnie.com) reported on some of our recent work in developing high-quality dual-energy imaging capabilities for portable radiography. Thanks to Paul De Jean, Yifu Ding, and Carestream collaborators for their great work on this project.
I-STAR Summer Barbecue a BLAST!

I-STAR Summer Barbecue a BLAST!
Warm sun, fun, and food marked the I-STAR Lab’s Summer Barbecue at Downs Memorial Park south of Baltimore.
Highlights of the day:
– A mean game of croquet…
– And an even meaner game of soccer!
– Way too much food
– Debut of the I-STAR T-Shirts!
The grand prize in the Beer Pong Trivia contest went to Ali Uneri — Congratulations, and enjoy the high-tech headphones!
I-STARs Come out to Shine at AAPM Philadelphia

Congratulations to eveyone for hard work and outstanding presentations at the annual meeting of the AAPM in Philly:
Grace Gang et al. “The Genralized NEQ and Detectability Index for Tomosynthesis and Cone-Beam CT”
Paul De Jean et al. “High-Performance Dual-Energy Imaging with a Wireless DR Detector: High-Quality Imaging in the ICU”
Sebastian Schafer et al. “Cone-Beam CT Guidance of Spine Surgery: Performance and Integration of a New High-Performance C-Arm Prototype”
Wojtek Zbijewski et al. “Design and Initial Performance of a Dedicated Cone-Beam CT System for Musculoskeletal Extremities Imaging”
Web Stayman et al. “Predicting Noise and Resolution Properties in Tomosynthesis with Statistical Image Reconstruction”
Jeff Siewerdsen et al. “C-Arm Cone-Beam CT: Essential Science and Practicalities”
I-STAR Lab Turns 1-Year Old

I-STAR Lab Turns 1-Year Old
The I-STAR Lab celebrated its first anniversary at Hopkins on July 1, 2010! It has been a fantastic year – a new lab space, new collaborations, fantastic students and staff, and a new home in Baltimore!
Top 5 Highlights of Our First Year:
5. Lab construction. (Thanks to Tom Judy, Bill Woodcock, and Elliot McVeigh for support!)
4. A new and improved imaging bench
3. C-arm moved to the Minimally Invasive Surgical Training and Innovation Center (MISTIC)
2. Fun, friends, warm weather, and great food in Baltimore!
1. … and BME!!!